Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn approach to dealing with missing values in heterogeneous data using k-nearest neighbors
Paper and Code
Aug 13, 2016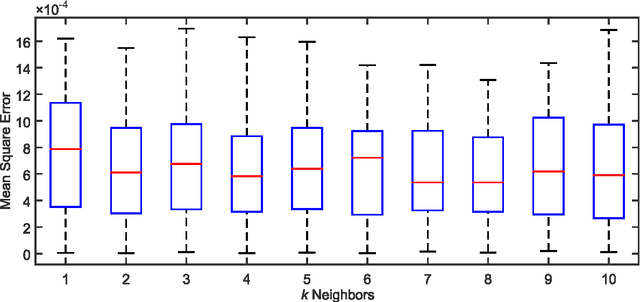

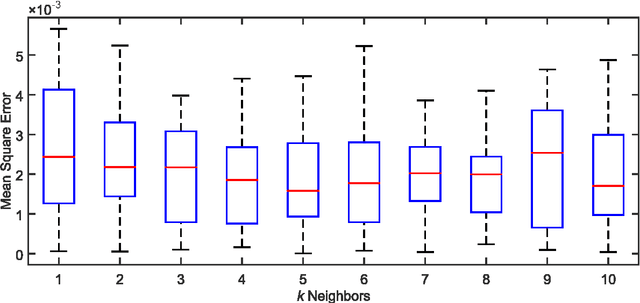

Techniques such as clusterization, neural networks and decision making usually rely on algorithms that are not well suited to deal with missing values. However, real world data frequently contains such cases. The simplest solution is to either substitute them by a best guess value or completely disregard the missing values. Unfortunately, both approaches can lead to biased results. In this paper, we propose a technique for dealing with missing values in heterogeneous data using imputation based on the k-nearest neighbors algorithm. It can handle real (which we refer to as crisp henceforward), interval and fuzzy data. The effectiveness of the algorithm is tested on several datasets and the numerical results are promising.
View paper on