 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Estimation of k for the Nearest Neighbors Class of Methods
Paper and Code
Jun 13, 2016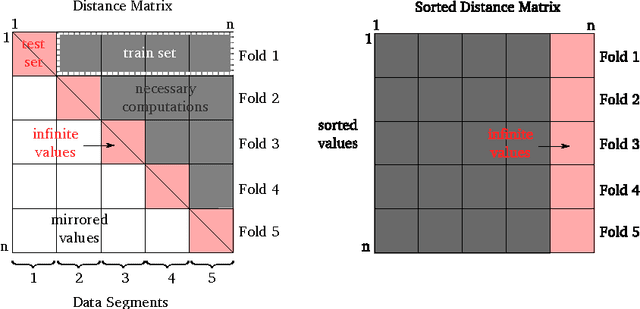
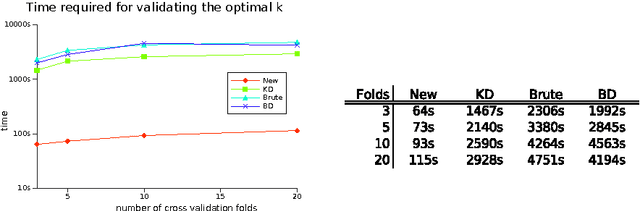
The k Nearest Neighbors (kNN) method has received much attention in the past decades, where some theoretical bounds on its performance were identified and where practical optimizations were proposed for making it work fairly well in high dimensional spaces and on large datasets. From countless experiments of the past it became widely accepted that the value of k has a significant impact on the performance of this method. However, the efficient optimization of this parameter has not received so much attention in literature. Today, the most common approach is to cross-validate or bootstrap this value for all values in question. This approach forces distances to be recomputed many times, even if efficient methods are used. Hence, estimating the optimal k can become expensive even on modern systems. Frequently, this circumstance leads to a sparse manual search of k. In this paper we want to point out that a systematic and thorough estimation of the parameter k can be performed efficiently. The discussed approach relies on large matrices, but we want to argue, that in practice a higher space complexity is often much less of a problem than repetitive distance computations.