 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-driven Simulations for Deep Convolutional Neural Networks
Paper and Code
May 31, 2016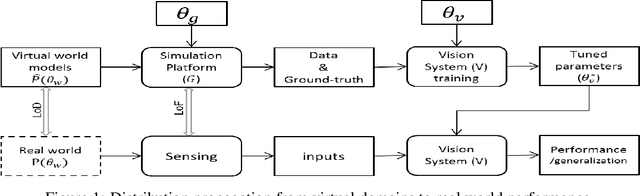
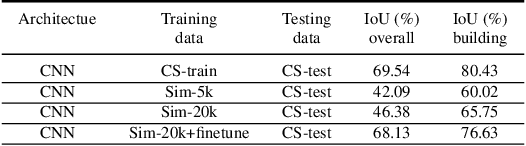
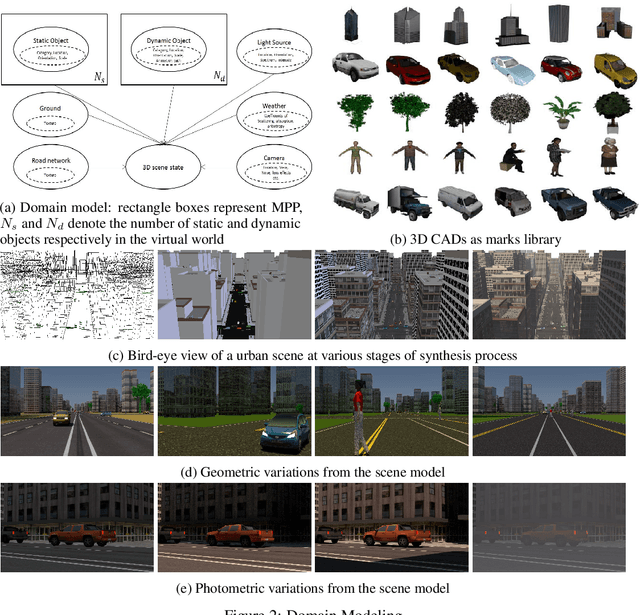

The use of simulated virtual environments to train deep convolutional neural networks (CNN) is a currently active practice to reduce the (real)data-hungriness of the deep CNN models, especially in application domains in which large scale real data and/or groundtruth acquisition is difficult or laborious. Recent approaches have attempted to harness the capabilities of existing video games, animated movies to provide training data with high precision groundtruth. However, a stumbling block is in how one can certify generalization of the learned models and their usefulness in real world data sets. This opens up fundamental questions such as: What is the role of photorealism of graphics simulations in training CNN models? Are the trained models valid in reality? What are possible ways to reduce the performance bias? In this work, we begin to address theses issues systematically in the context of urban semantic understanding with CNNs. Towards this end, we (a) propose a simple probabilistic urban scene model, (b) develop a parametric rendering tool to synthesize the data with groundtruth, followed by (c) a systematic exploration of the impact of level-of-realism on the generality of the trained CNN model to real world; and domain adaptation concepts to minimize the performance bias.