 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoing Deeper for Multilingual Visual Sentiment Detection
Paper and Code

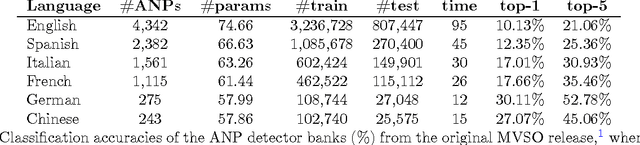
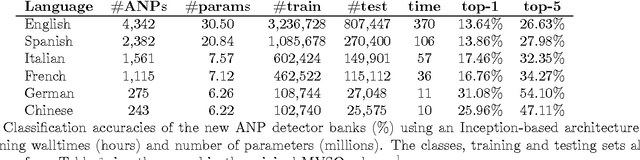
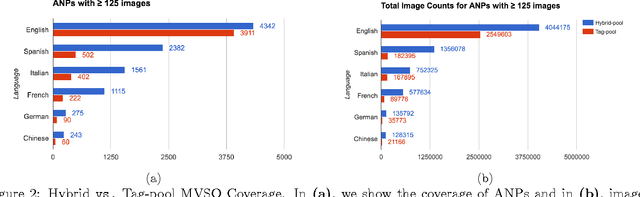
This technical report details several improvements to the visual concept detector banks built on images from the Multilingual Visual Sentiment Ontology (MVSO). The detector banks are trained to detect a total of 9,918 sentiment-biased visual concepts from six major languages: English, Spanish, Italian, French, German and Chinese. In the original MVSO release, adjective-noun pair (ANP) detectors were trained for the six languages using an AlexNet-styled architecture by fine-tuning from DeepSentiBank. Here, through a more extensive set of experiments, parameter tuning, and training runs, we detail and release higher accuracy models for detecting ANPs across six languages from the same image pool and setting as in the original release using a more modern architecture, GoogLeNet, providing comparable or better performance with reduced network parameter cost. In addition, since the image pool in MVSO can be corrupted by user noise from social interactions, we partitioned out a sub-corpus of MVSO images based on tag-restricted queries for higher fidelity labels. We show that as a result of these higher fidelity labels, higher performing AlexNet-styled ANP detectors can be trained using the tag-restricted image subset as compared to the models in full corpus. We release all these newly trained models for public research use along with the list of tag-restricted images from the MVSO dataset.