 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSS4MCT: A Statistical Stemmer for Morphologically Complex Texts
Paper and Code
Jun 20, 2016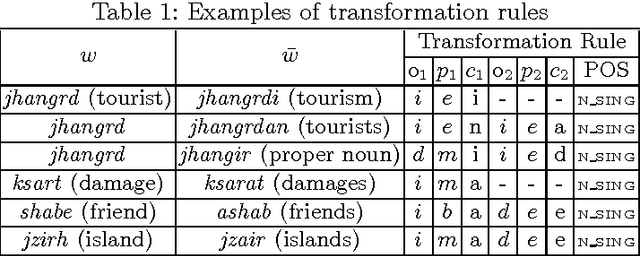
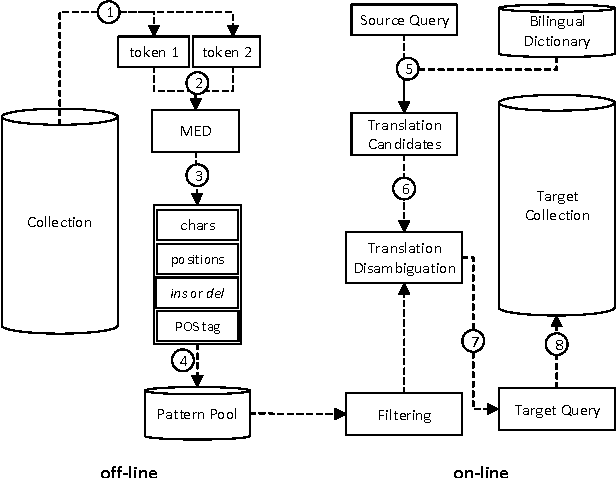

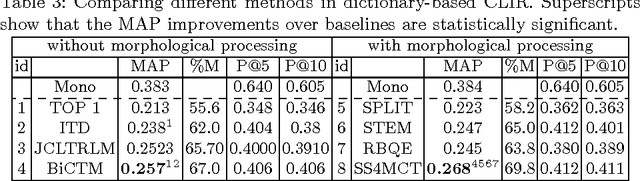
There have been multiple attempts to resolve various inflection matching problems in information retrieval. Stemming is a common approach to this end. Among many techniques for stemming, statistical stemming has been shown to be effective in a number of languages, particularly highly inflected languages. In this paper we propose a method for finding affixes in different positions of a word. Common statistical techniques heavily rely on string similarity in terms of prefix and suffix matching. Since infixes are common in irregular/informal inflections in morphologically complex texts, it is required to find infixes for stemming. In this paper we propose a method whose aim is to find statistical inflectional rules based on minimum edit distance table of word pairs and the likelihoods of the rules in a language. These rules are used to statistically stem words and can be used in different text mining tasks. Experimental results on CLEF 2008 and CLEF 2009 English-Persian CLIR tasks indicate that the proposed method significantly outperforms all the baselines in terms of MAP.