 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputing Web-scale Topic Models using an Asynchronous Parameter Server
Paper and Code
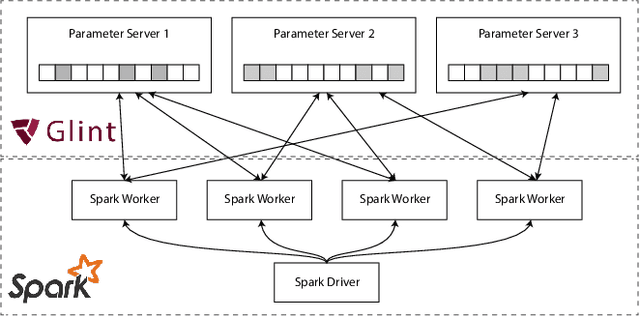
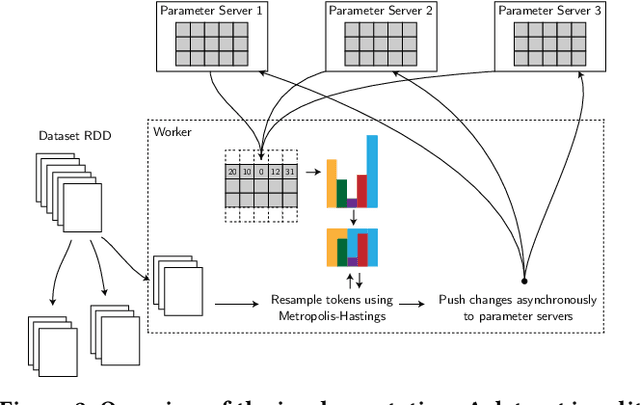
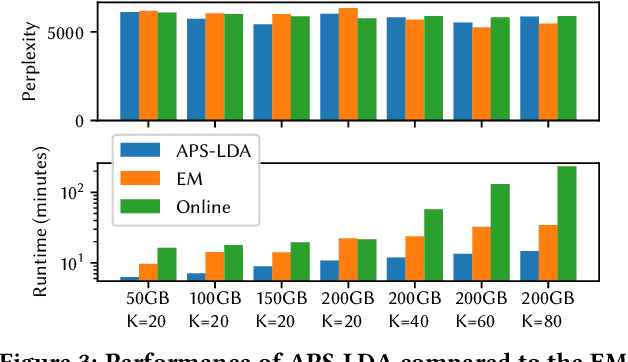
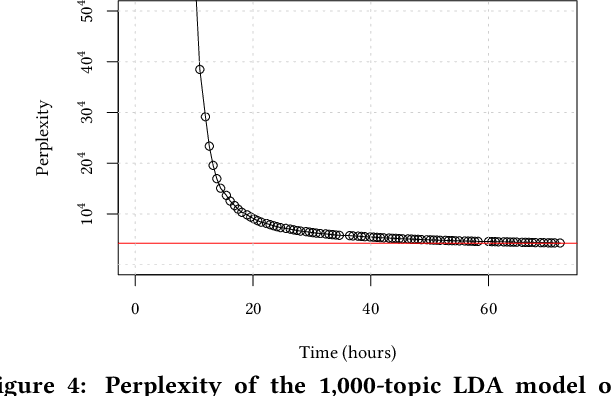
Topic models such as Latent Dirichlet Allocation (LDA) have been widely used in information retrieval for tasks ranging from smoothing and feedback methods to tools for exploratory search and discovery. However, classical methods for inferring topic models do not scale up to the massive size of today's publicly available Web-scale data sets. The state-of-the-art approaches rely on custom strategies, implementations and hardware to facilitate their asynchronous, communication-intensive workloads. We present APS-LDA, which integrates state-of-the-art topic modeling with cluster computing frameworks such as Spark using a novel asynchronous parameter server. Advantages of this integration include convenient usage of existing data processing pipelines and eliminating the need for disk writes as data can be kept in memory from start to finish. Our goal is not to outperform highly customized implementations, but to propose a general high-performance topic modeling framework that can easily be used in today's data processing pipelines. We compare APS-LDA to the existing Spark LDA implementations and show that our system can, on a 480-core cluster, process up to 135 times more data and 10 times more topics without sacrificing model quality.