 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsk Your Neurons: A Deep Learning Approach to Visual Question Answering
Paper and Code
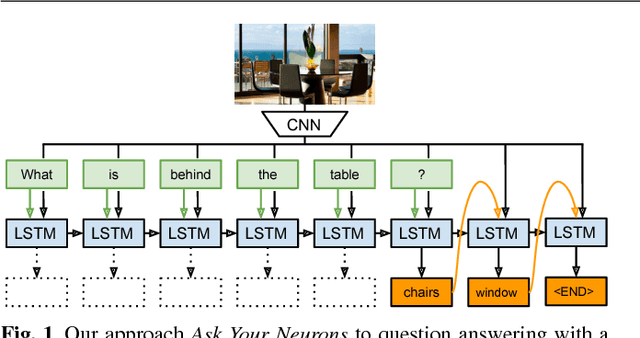
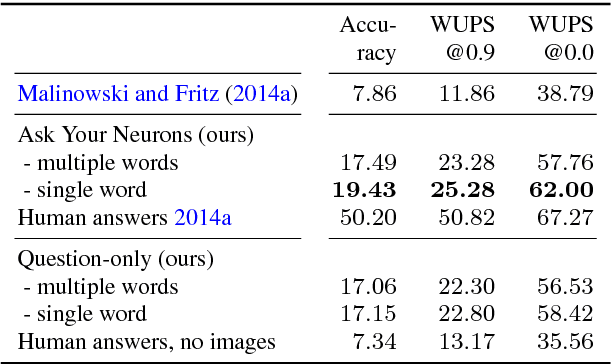
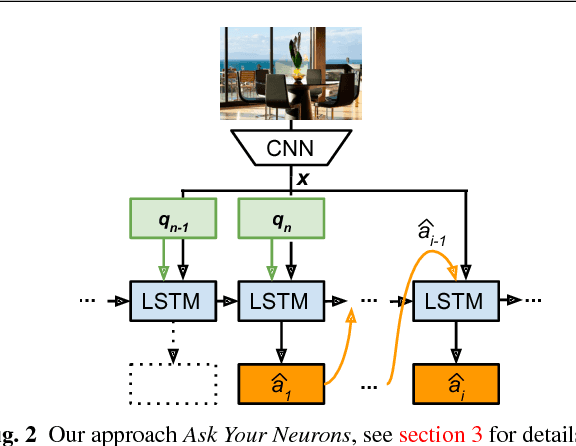
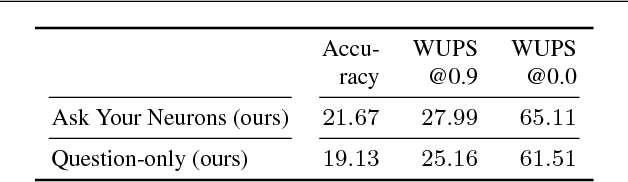
We address a question answering task on real-world images that is set up as a Visual Turing Test. By combining latest advances in image representation and natural language processing, we propose Ask Your Neurons, a scalable, jointly trained, end-to-end formulation to this problem. In contrast to previous efforts, we are facing a multi-modal problem where the language output (answer) is conditioned on visual and natural language inputs (image and question). We provide additional insights into the problem by analyzing how much information is contained only in the language part for which we provide a new human baseline. To study human consensus, which is related to the ambiguities inherent in this challenging task, we propose two novel metrics and collect additional answers which extend the original DAQUAR dataset to DAQUAR-Consensus. Moreover, we also extend our analysis to VQA, a large-scale question answering about images dataset, where we investigate some particular design choices and show the importance of stronger visual models. At the same time, we achieve strong performance of our model that still uses a global image representation. Finally, based on such analysis, we refine our Ask Your Neurons on DAQUAR, which also leads to a better performance on this challenging task.