 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Channel Speech Enhancement Using Outlier Detection
Paper and Code
May 04, 2016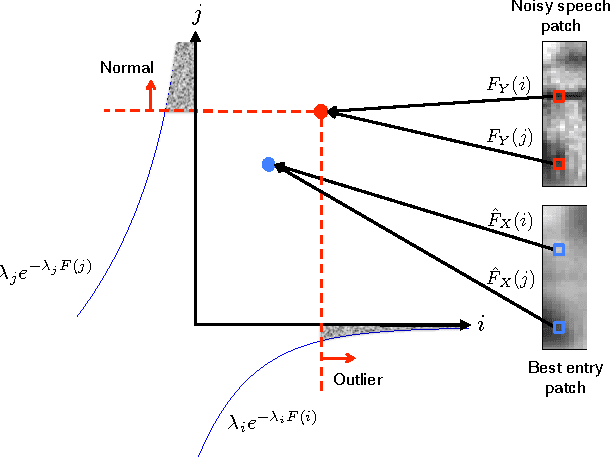
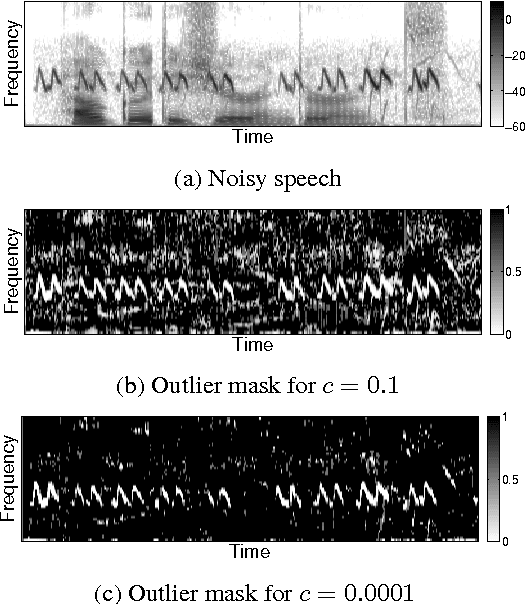
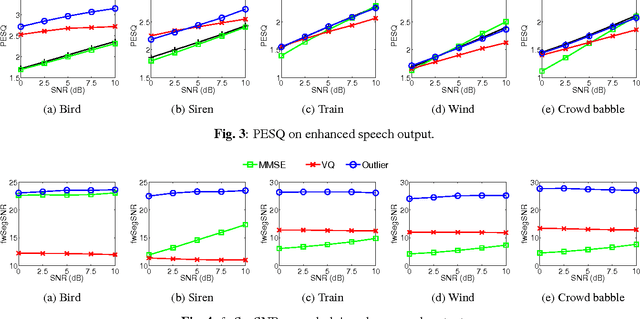
Distortion of the underlying speech is a common problem for single-channel speech enhancement algorithms, and hinders such methods from being used more extensively. A dictionary based speech enhancement method that emphasizes preserving the underlying speech is proposed. Spectral patches of clean speech are sampled and clustered to train a dictionary. Given a noisy speech spectral patch, the best matching dictionary entry is selected and used to estimate the noise power at each time-frequency bin. The noise estimation step is formulated as an outlier detection problem, where the noise at each bin is assumed present only if it is an outlier to the corresponding bin of the best matching dictionary entry. This framework assigns higher priority in removing spectral elements that strongly deviate from a typical spoken unit stored in the trained dictionary. Even without the aid of a separate noise model, this method can achieve significant noise reduction for various non-stationary noises, while effectively preserving the underlying speech in more challenging noisy environments.