 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity Type Recognition using an Ensemble of Distributional Semantic Models to Enhance Query Understanding
Paper and Code
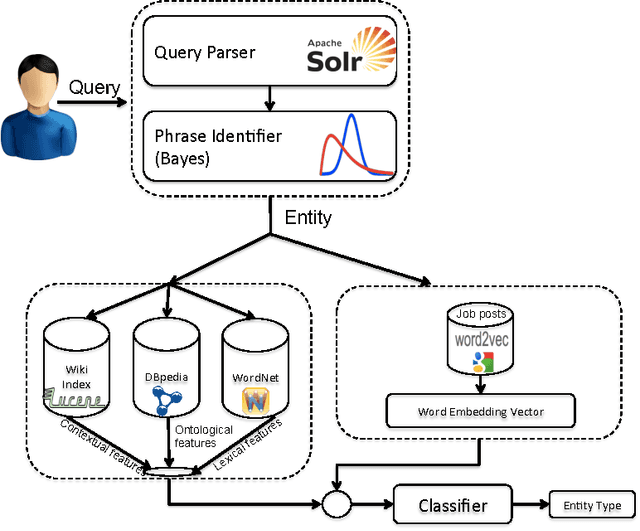
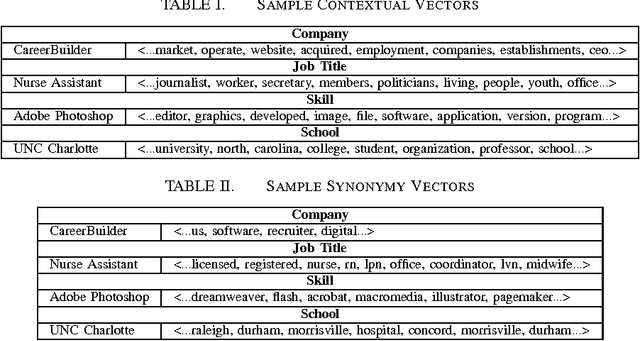
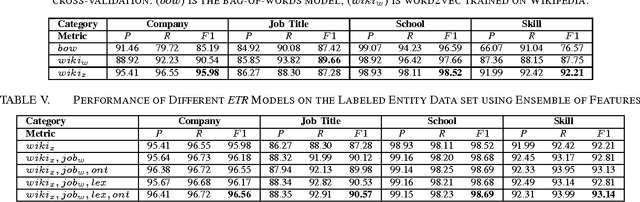
We present an ensemble approach for categorizing search query entities in the recruitment domain. Understanding the types of entities expressed in a search query (Company, Skill, Job Title, etc.) enables more intelligent information retrieval based upon those entities compared to a traditional keyword-based search. Because search queries are typically very short, leveraging a traditional bag-of-words model to identify entity types would be inappropriate due to the lack of contextual information. Our approach instead combines clues from different sources of varying complexity in order to collect real-world knowledge about query entities. We employ distributional semantic representations of query entities through two models: 1) contextual vectors generated from encyclopedic corpora like Wikipedia, and 2) high dimensional word embedding vectors generated from millions of job postings using word2vec. Additionally, our approach utilizes both entity linguistic properties obtained from WordNet and ontological properties extracted from DBpedia. We evaluate our approach on a data set created at CareerBuilder; the largest job board in the US. The data set contains entities extracted from millions of job seekers/recruiters search queries, job postings, and resume documents. After constructing the distributional vectors of search entities, we use supervised machine learning to infer search entity types. Empirical results show that our approach outperforms the state-of-the-art word2vec distributional semantics model trained on Wikipedia. Moreover, we achieve micro-averaged F 1 score of 97% using the proposed distributional representations ensemble.