 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePart-of-Speech Tagging for Code-mixed Indian Social Media Text at ICON 2015
Paper and Code
Jan 06, 2016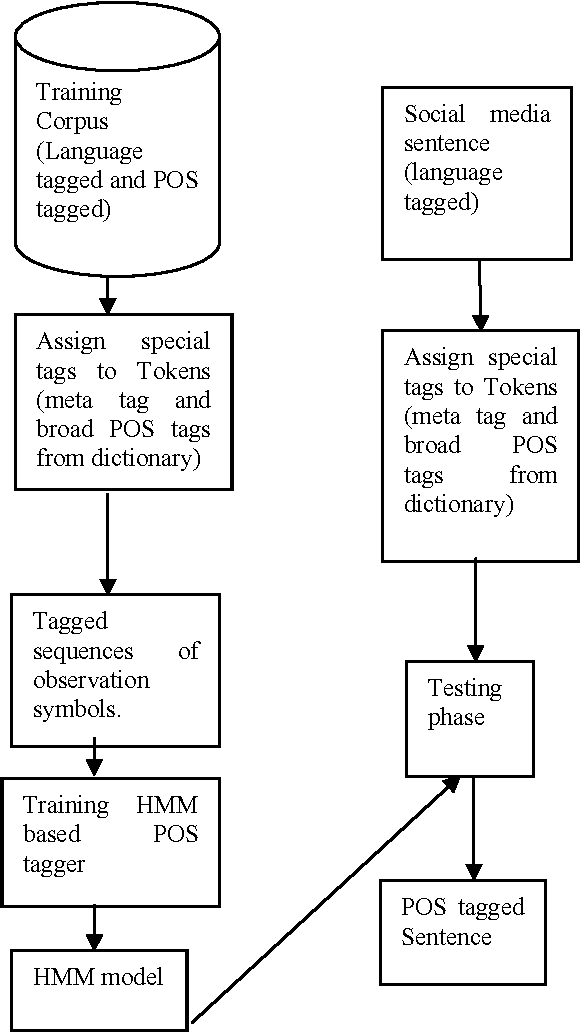
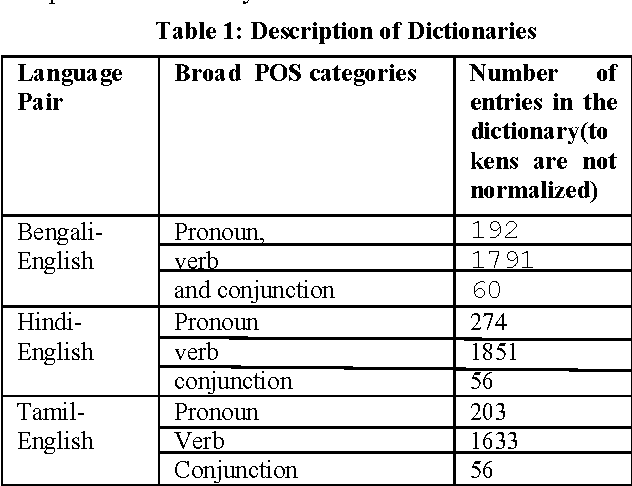
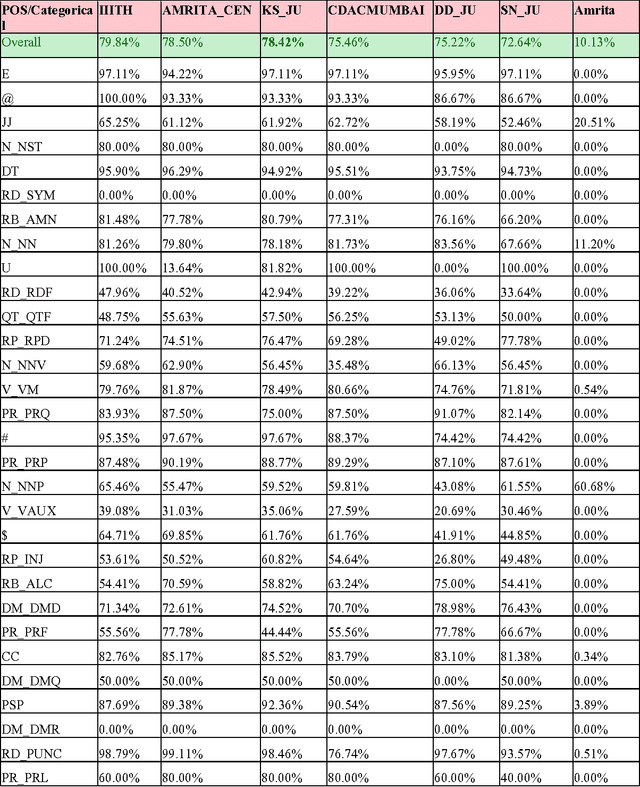
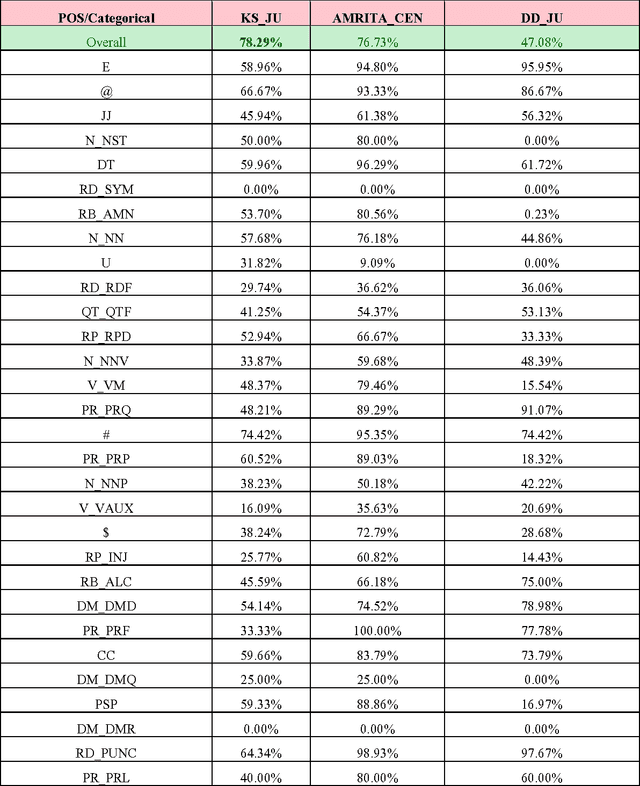
This paper discusses the experiments carried out by us at Jadavpur University as part of the participation in ICON 2015 task: POS Tagging for Code-mixed Indian Social Media Text. The tool that we have developed for the task is based on Trigram Hidden Markov Model that utilizes information from dictionary as well as some other word level features to enhance the observation probabilities of the known tokens as well as unknown tokens. We submitted runs for Bengali-English, Hindi-English and Tamil-English Language pairs. Our system has been trained and tested on the datasets released for ICON 2015 shared task: POS Tagging For Code-mixed Indian Social Media Text. In constrained mode, our system obtains average overall accuracy (averaged over all three language pairs) of 75.60% which is very close to other participating two systems (76.79% for IIITH and 75.79% for AMRITA_CEN) ranked higher than our system. In unconstrained mode, our system obtains average overall accuracy of 70.65% which is also close to the system (72.85% for AMRITA_CEN) which obtains the highest average overall accuracy.