 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrue Online Temporal-Difference Learning
Paper and Code
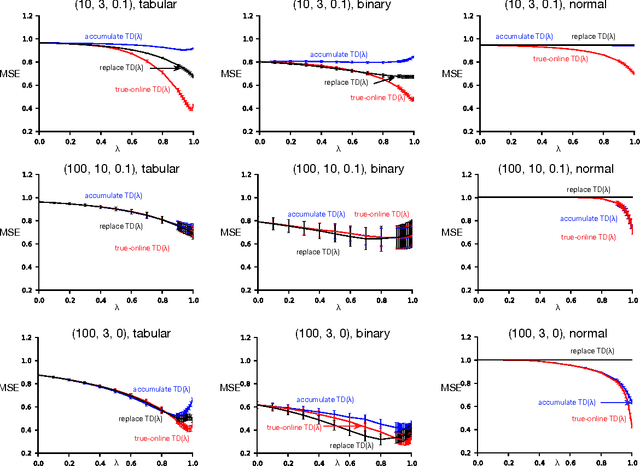
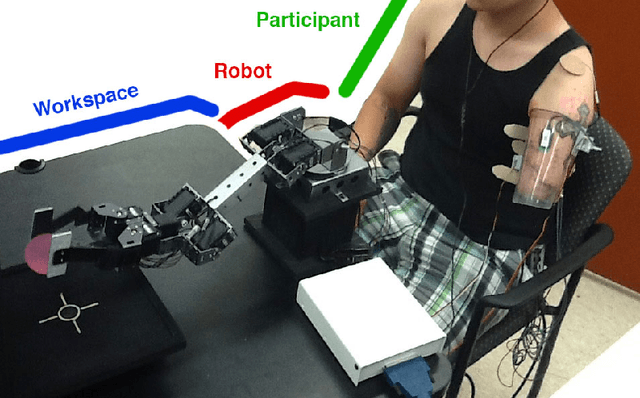
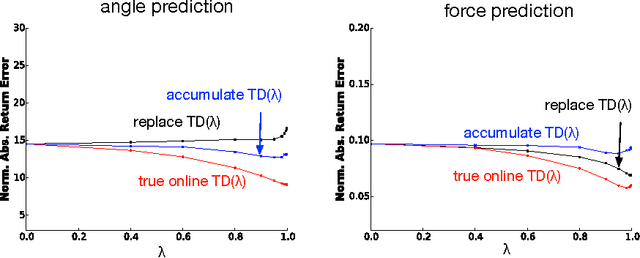
The temporal-difference methods TD($\lambda$) and Sarsa($\lambda$) form a core part of modern reinforcement learning. Their appeal comes from their good performance, low computational cost, and their simple interpretation, given by their forward view. Recently, new versions of these methods were introduced, called true online TD($\lambda$) and true online Sarsa($\lambda$), respectively (van Seijen & Sutton, 2014). These new versions maintain an exact equivalence with the forward view at all times, whereas the traditional versions only approximate it for small step-sizes. We hypothesize that these true online methods not only have better theoretical properties, but also dominate the regular methods empirically. In this article, we put this hypothesis to the test by performing an extensive empirical comparison. Specifically, we compare the performance of true online TD($\lambda$)/Sarsa($\lambda$) with regular TD($\lambda$)/Sarsa($\lambda$) on random MRPs, a real-world myoelectric prosthetic arm, and a domain from the Arcade Learning Environment. We use linear function approximation with tabular, binary, and non-binary features. Our results suggest that the true online methods indeed dominate the regular methods. Across all domains/representations the learning speed of the true online methods are often better, but never worse than that of the regular methods. An additional advantage is that no choice between traces has to be made for the true online methods. Besides the empirical results, we provide an in-depth analysis of the theory behind true online temporal-difference learning. In addition, we show that new true online temporal-difference methods can be derived by making changes to the online forward view and then rewriting the update equations.