 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn analysis of the factors affecting keypoint stability in scale-space
Paper and Code
Nov 26, 2015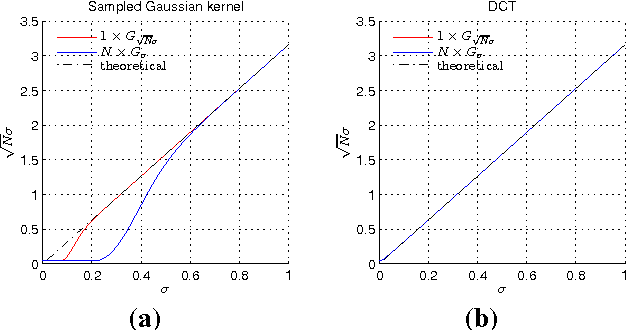

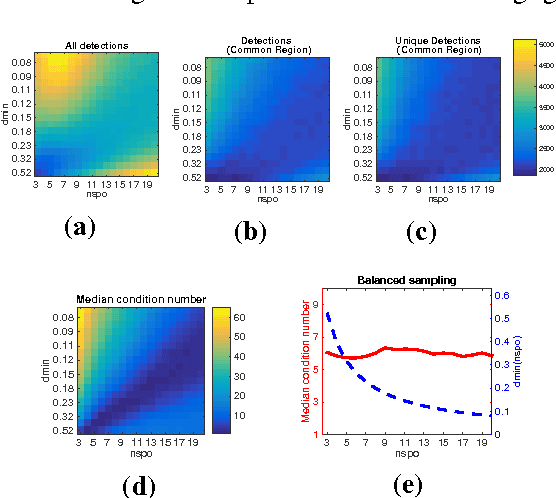
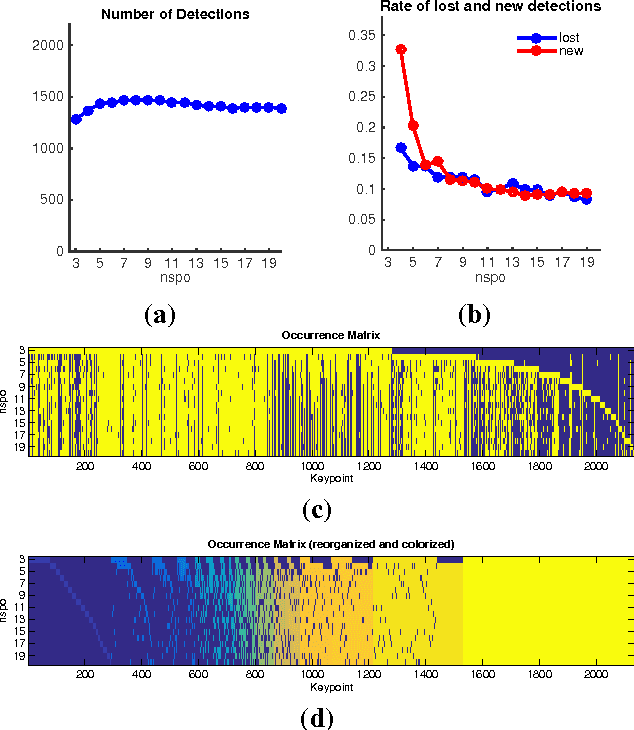
The most popular image matching algorithm SIFT, introduced by D. Lowe a decade ago, has proven to be sufficiently scale invariant to be used in numerous applications. In practice, however, scale invariance may be weakened by various sources of error inherent to the SIFT implementation affecting the stability and accuracy of keypoint detection. The density of the sampling of the Gaussian scale-space and the level of blur in the input image are two of these sources. This article presents a numerical analysis of their impact on the extracted keypoints stability. Such an analysis has both methodological and practical implications, on how to compare feature detectors and on how to improve SIFT. We show that even with a significantly oversampled scale-space numerical errors prevent from achieving perfect stability. Usual strategies to filter out unstable detections are shown to be inefficient. We also prove that the effect of the error in the assumption on the initial blur is asymmetric and that the method is strongly degraded in presence of aliasing or without a correct assumption on the camera blur.