Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Benefits of Deep Feedforward Networks
Paper and Code
Sep 29, 2015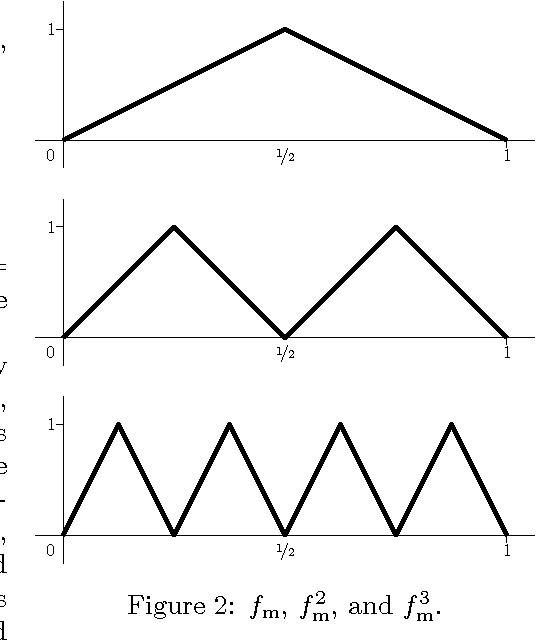
This note provides a family of classification problems, indexed by a positive integer $k$, where all shallow networks with fewer than exponentially (in $k$) many nodes exhibit error at least $1/6$, whereas a deep network with 2 nodes in each of $2k$ layers achieves zero error, as does a recurrent network with 3 distinct nodes iterated $k$ times. The proof is elementary, and the networks are standard feedforward networks with ReLU (Rectified Linear Unit) nonlinearities.
View paper on