 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartitioning Large Scale Deep Belief Networks Using Dropout
Paper and Code
Aug 28, 2015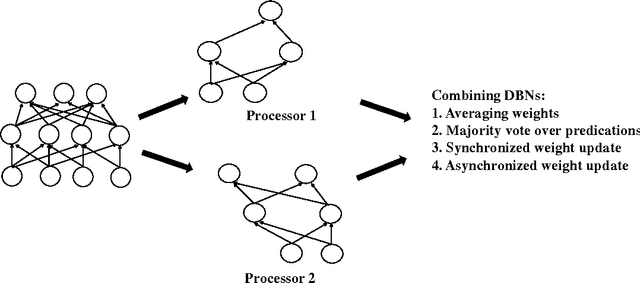
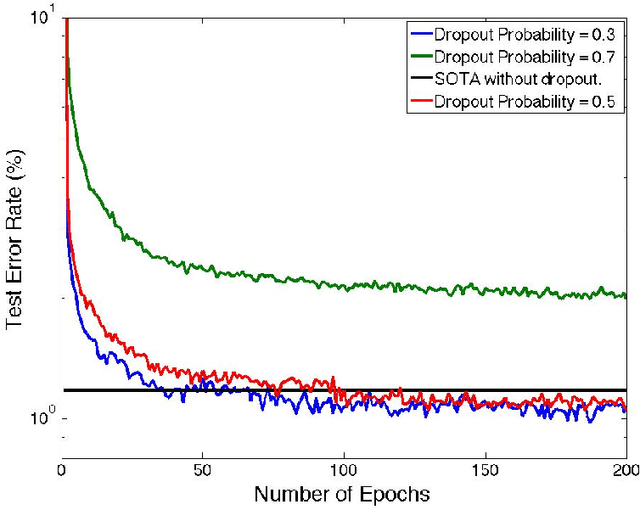
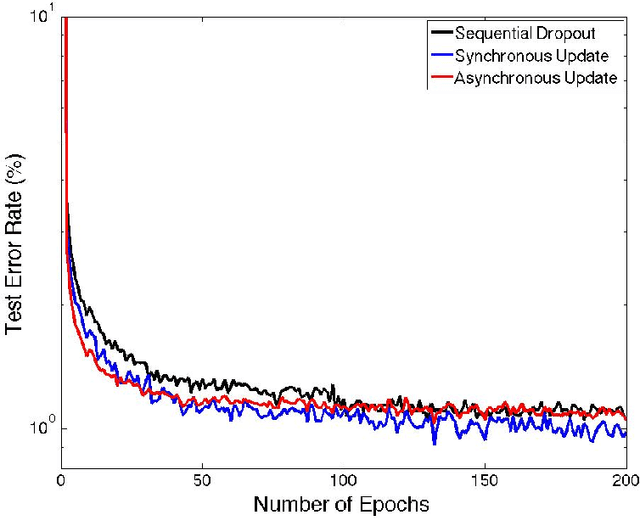
Deep learning methods have shown great promise in many practical applications, ranging from speech recognition, visual object recognition, to text processing. However, most of the current deep learning methods suffer from scalability problems for large-scale applications, forcing researchers or users to focus on small-scale problems with fewer parameters. In this paper, we consider a well-known machine learning model, deep belief networks (DBNs) that have yielded impressive classification performance on a large number of benchmark machine learning tasks. To scale up DBN, we propose an approach that can use the computing clusters in a distributed environment to train large models, while the dense matrix computations within a single machine are sped up using graphics processors (GPU). When training a DBN, each machine randomly drops out a portion of neurons in each hidden layer, for each training case, making the remaining neurons only learn to detect features that are generally helpful for producing the correct answer. Within our approach, we have developed four methods to combine outcomes from each machine to form a unified model. Our preliminary experiment on the mnst handwritten digit database demonstrates that our approach outperforms the state of the art test error rate.