 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mood-based Genre Classification of Television Content
Paper and Code
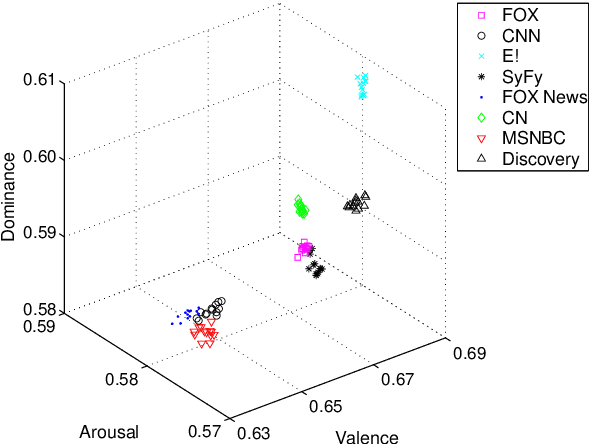
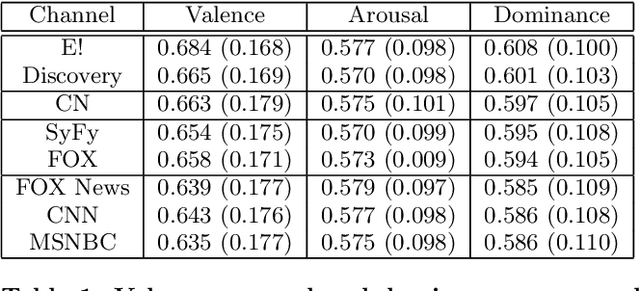
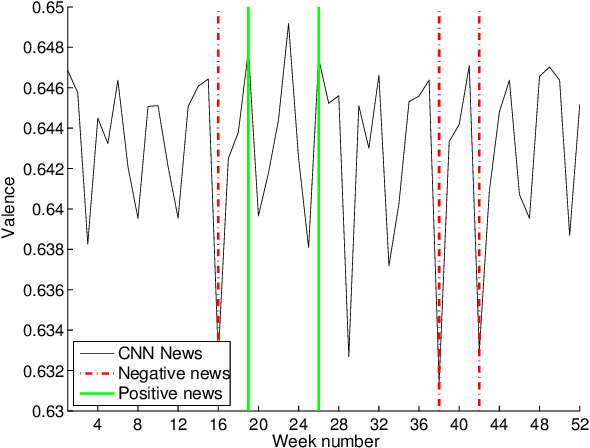
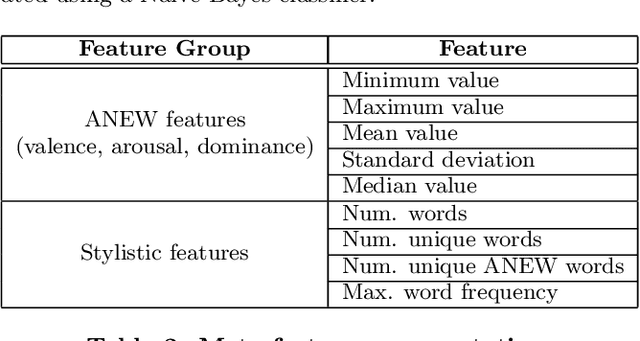
The classification of television content helps users organise and navigate through the large list of channels and programs now available. In this paper, we address the problem of television content classification by exploiting text information extracted from program transcriptions. We present an analysis which adapts a model for sentiment that has been widely and successfully applied in other fields such as music or blog posts. We use a real-world dataset obtained from the Boxfish API to compare the performance of classifiers trained on a number of different feature sets. Our experiments show that, over a large collection of television content, program genres can be represented in a three-dimensional space of valence, arousal and dominance, and that promising classification results can be achieved using features based on this representation. This finding supports the use of the proposed representation of television content as a feature space for similarity computation and recommendation generation.