 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwitter Sentiment Analysis: Lexicon Method, Machine Learning Method and Their Combination
Paper and Code

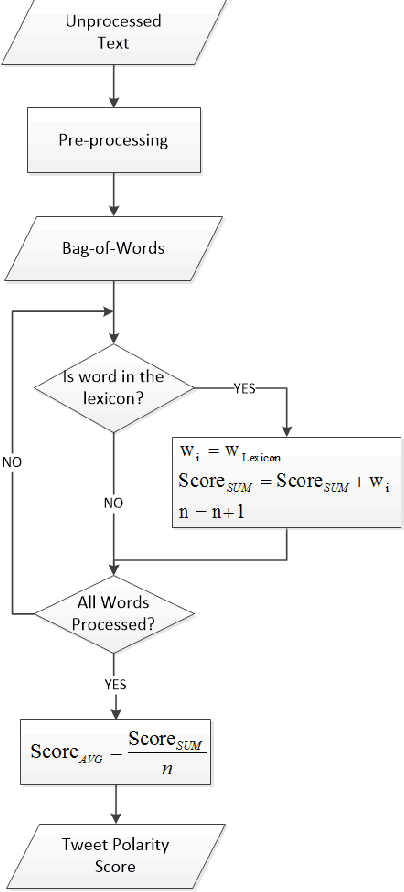

This paper covers the two approaches for sentiment analysis: i) lexicon based method; ii) machine learning method. We describe several techniques to implement these approaches and discuss how they can be adopted for sentiment classification of Twitter messages. We present a comparative study of different lexicon combinations and show that enhancing sentiment lexicons with emoticons, abbreviations and social-media slang expressions increases the accuracy of lexicon-based classification for Twitter. We discuss the importance of feature generation and feature selection processes for machine learning sentiment classification. To quantify the performance of the main sentiment analysis methods over Twitter we run these algorithms on a benchmark Twitter dataset from the SemEval-2013 competition, task 2-B. The results show that machine learning method based on SVM and Naive Bayes classifiers outperforms the lexicon method. We present a new ensemble method that uses a lexicon based sentiment score as input feature for the machine learning approach. The combined method proved to produce more precise classifications. We also show that employing a cost-sensitive classifier for highly unbalanced datasets yields an improvement of sentiment classification performance up to 7%.