 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Nearly Optimal and Agnostic Algorithm for Properly Learning a Mixture of k Gaussians, for any Constant k
Paper and Code
Jun 03, 2015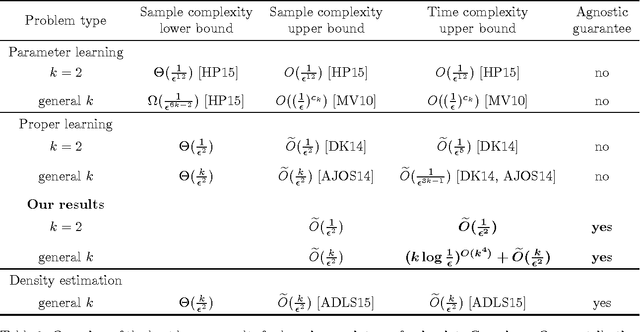
Learning a Gaussian mixture model (GMM) is a fundamental problem in machine learning, learning theory, and statistics. One notion of learning a GMM is proper learning: here, the goal is to find a mixture of $k$ Gaussians $\mathcal{M}$ that is close to the density $f$ of the unknown distribution from which we draw samples. The distance between $\mathcal{M}$ and $f$ is typically measured in the total variation or $L_1$-norm. We give an algorithm for learning a mixture of $k$ univariate Gaussians that is nearly optimal for any fixed $k$. The sample complexity of our algorithm is $\tilde{O}(\frac{k}{\epsilon^2})$ and the running time is $(k \cdot \log\frac{1}{\epsilon})^{O(k^4)} + \tilde{O}(\frac{k}{\epsilon^2})$. It is well-known that this sample complexity is optimal (up to logarithmic factors), and it was already achieved by prior work. However, the best known time complexity for proper learning a $k$-GMM was $\tilde{O}(\frac{1}{\epsilon^{3k-1}})$. In particular, the dependence between $\frac{1}{\epsilon}$ and $k$ was exponential. We significantly improve this dependence by replacing the $\frac{1}{\epsilon}$ term with a $\log \frac{1}{\epsilon}$ while only increasing the exponent moderately. Hence, for any fixed $k$, the $\tilde{O} (\frac{k}{\epsilon^2})$ term dominates our running time, and thus our algorithm runs in time which is nearly-linear in the number of samples drawn. Achieving a running time of $\textrm{poly}(k, \frac{1}{\epsilon})$ for proper learning of $k$-GMMs has recently been stated as an open problem by multiple researchers, and we make progress on this question. Moreover, our approach offers an agnostic learning guarantee: our algorithm returns a good GMM even if the distribution we are sampling from is not a mixture of Gaussians. To the best of our knowledge, our algorithm is the first agnostic proper learning algorithm for GMMs.