 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling meaning: computational interpreting and understanding of natural language fragments
Paper and Code
Jun 29, 2016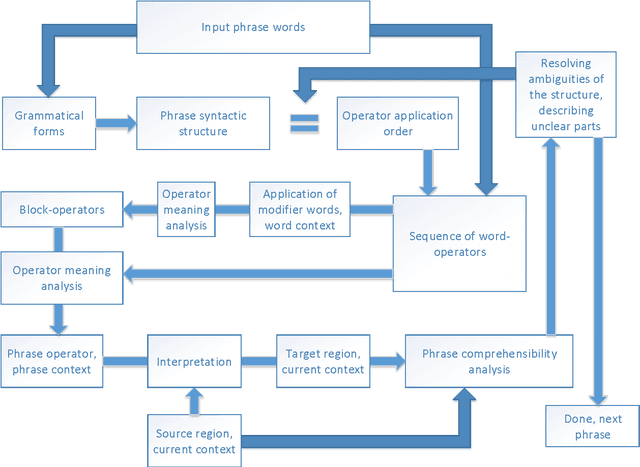
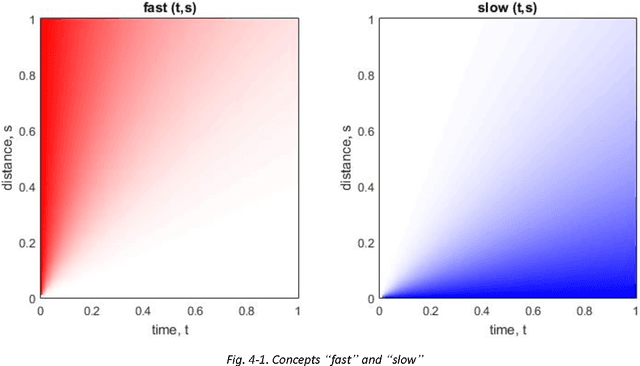
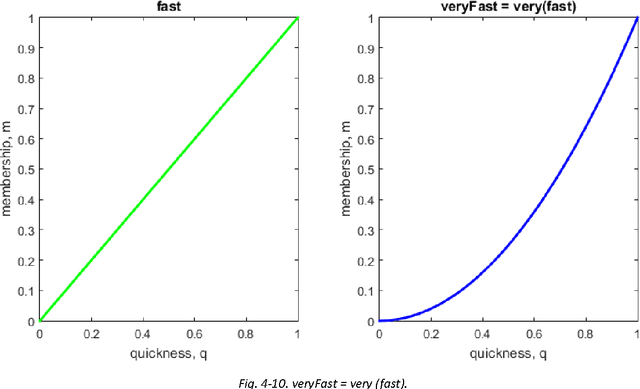
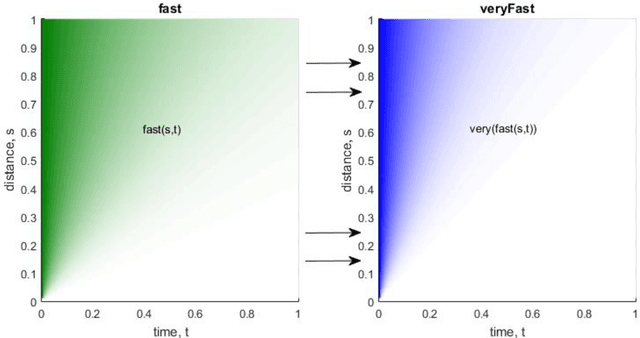
In this introductory article we present the basics of an approach to implementing computational interpreting of natural language aiming to model the meanings of words and phrases. Unlike other approaches, we attempt to define the meanings of text fragments in a composable and computer interpretable way. We discuss models and ideas for detecting different types of semantic incomprehension and choosing the interpretation that makes most sense in a given context. Knowledge representation is designed for handling context-sensitive and uncertain / imprecise knowledge, and for easy accommodation of new information. It stores quantitative information capturing the essence of the concepts, because it is crucial for working with natural language understanding and reasoning. Still, the representation is general enough to allow for new knowledge to be learned, and even generated by the system. The article concludes by discussing some reasoning-related topics: possible approaches to generation of new abstract concepts, and describing situations and concepts in words (e.g. for specifying interpretation difficulties).