 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundational principles for large scale inference: Illustrations through correlation mining
Paper and Code
May 18, 2015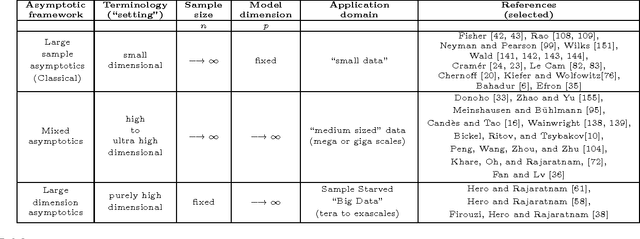

When can reliable inference be drawn in the "Big Data" context? This paper presents a framework for answering this fundamental question in the context of correlation mining, with implications for general large scale inference. In large scale data applications like genomics, connectomics, and eco-informatics the dataset is often variable-rich but sample-starved: a regime where the number $n$ of acquired samples (statistical replicates) is far fewer than the number $p$ of observed variables (genes, neurons, voxels, or chemical constituents). Much of recent work has focused on understanding the computational complexity of proposed methods for "Big Data." Sample complexity however has received relatively less attention, especially in the setting when the sample size $n$ is fixed, and the dimension $p$ grows without bound. To address this gap, we develop a unified statistical framework that explicitly quantifies the sample complexity of various inferential tasks. Sampling regimes can be divided into several categories: 1) the classical asymptotic regime where the variable dimension is fixed and the sample size goes to infinity; 2) the mixed asymptotic regime where both variable dimension and sample size go to infinity at comparable rates; 3) the purely high dimensional asymptotic regime where the variable dimension goes to infinity and the sample size is fixed. Each regime has its niche but only the latter regime applies to exa-scale data dimension. We illustrate this high dimensional framework for the problem of correlation mining, where it is the matrix of pairwise and partial correlations among the variables that are of interest. We demonstrate various regimes of correlation mining based on the unifying perspective of high dimensional learning rates and sample complexity for different structured covariance models and different inference tasks.