 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling State-Conditional Observation Distribution using Weighted Stereo Samples for Factorial Speech Processing Models
Paper and Code
Oct 05, 2016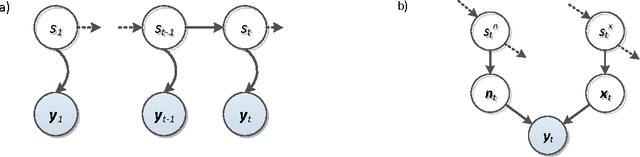

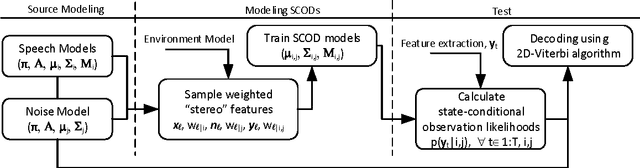
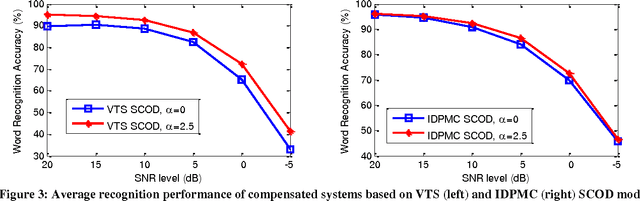
This paper investigates the effectiveness of factorial speech processing models in noise-robust automatic speech recognition tasks. For this purpose, the paper proposes an idealistic approach for modeling state-conditional observation distribution of factorial models based on weighted stereo samples. This approach is an extension to previous single pass retraining for ideal model compensation which is extended here to support multiple audio sources. Non-stationary noises can be considered as one of these audio sources with multiple states. Experiments of this paper over the set A of the Aurora 2 dataset show that recognition performance can be improved by this consideration. The improvement is significant in low signal to noise energy conditions, up to 4% absolute word recognition accuracy. In addition to the power of the proposed method in accurate representation of state-conditional observation distribution, it has an important advantage over previous methods by providing the opportunity to independently select feature spaces for both source and corrupted features. This opens a new window for seeking better feature spaces appropriate for noisy speech, independent from clean speech features.