 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid coding of visual content and local image features
Paper and Code
Feb 27, 2015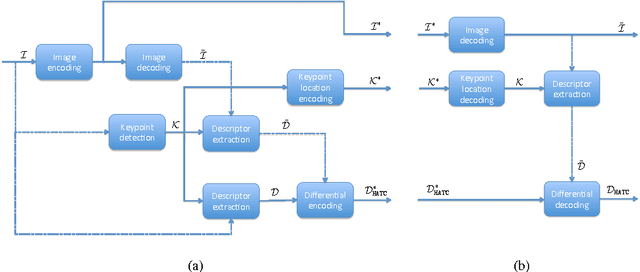
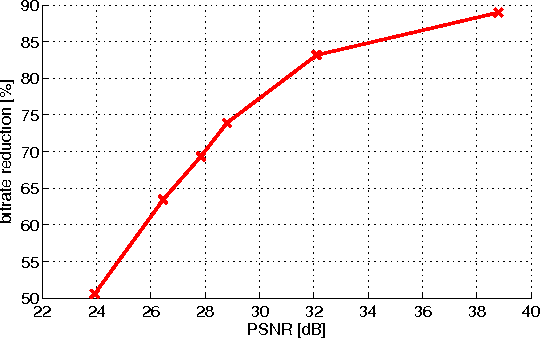
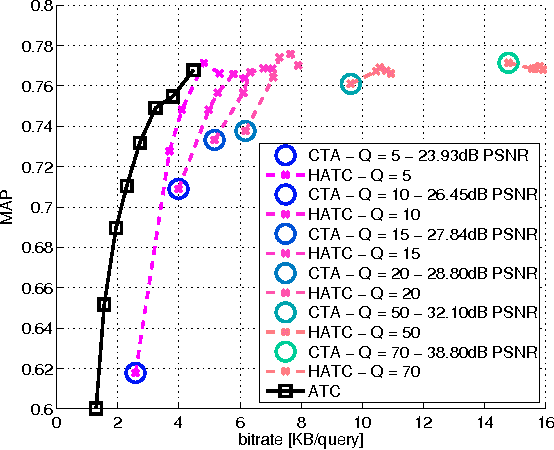
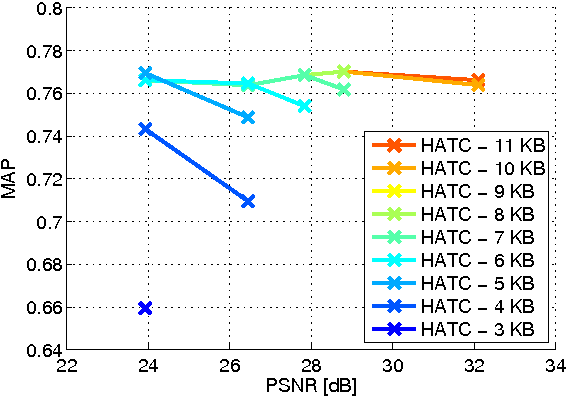
Distributed visual analysis applications, such as mobile visual search or Visual Sensor Networks (VSNs) require the transmission of visual content on a bandwidth-limited network, from a peripheral node to a processing unit. Traditionally, a Compress-Then-Analyze approach has been pursued, in which sensing nodes acquire and encode the pixel-level representation of the visual content, that is subsequently transmitted to a sink node in order to be processed. This approach might not represent the most effective solution, since several analysis applications leverage a compact representation of the content, thus resulting in an inefficient usage of network resources. Furthermore, coding artifacts might significantly impact the accuracy of the visual task at hand. To tackle such limitations, an orthogonal approach named Analyze-Then-Compress has been proposed. According to such a paradigm, sensing nodes are responsible for the extraction of visual features, that are encoded and transmitted to a sink node for further processing. In spite of improved task efficiency, such paradigm implies the central processing node not being able to reconstruct a pixel-level representation of the visual content. In this paper we propose an effective compromise between the two paradigms, namely Hybrid-Analyze-Then-Compress (HATC) that aims at jointly encoding visual content and local image features. Furthermore, we show how a target tradeoff between image quality and task accuracy might be achieved by accurately allocating the bitrate to either visual content or local features.