 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Batchwise Monotone Algorithm for Dictionary Learning
Paper and Code
Jan 31, 2015
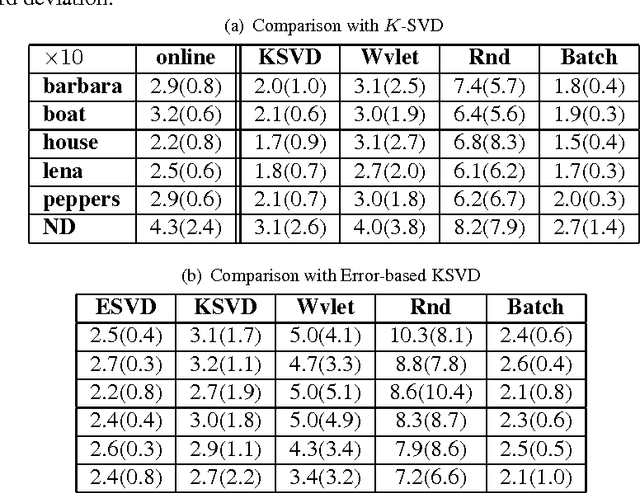
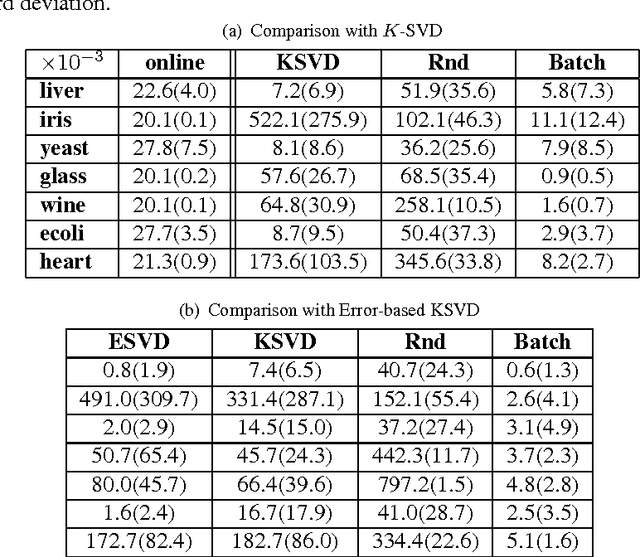
We propose a batchwise monotone algorithm for dictionary learning. Unlike the state-of-the-art dictionary learning algorithms which impose sparsity constraints on a sample-by-sample basis, we instead treat the samples as a batch, and impose the sparsity constraint on the whole. The benefit of batchwise optimization is that the non-zeros can be better allocated across the samples, leading to a better approximation of the whole. To accomplish this, we propose procedures to switch non-zeros in both rows and columns in the support of the coefficient matrix to reduce the reconstruction error. We prove in the proposed support switching procedure the objective of the algorithm, i.e., the reconstruction error, decreases monotonically and converges. Furthermore, we introduce a block orthogonal matching pursuit algorithm that also operates on sample batches to provide a warm start. Experiments on both natural image patches and UCI data sets show that the proposed algorithm produces a better approximation with the same sparsity levels compared to the state-of-the-art algorithms.