 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersian Sentiment Analyzer: A Framework based on a Novel Feature Selection Method
Paper and Code
Dec 27, 2014
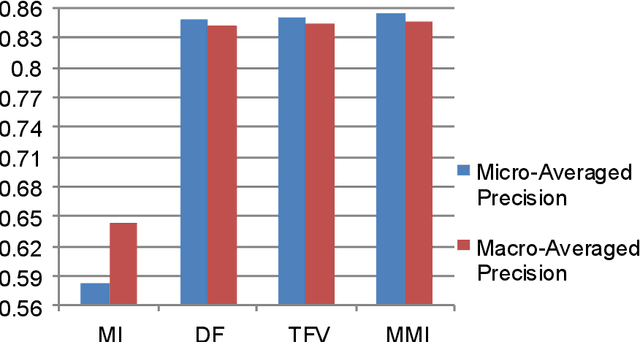
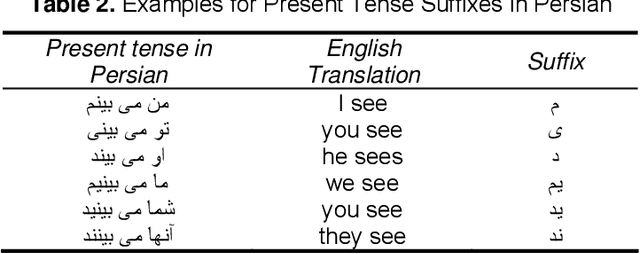
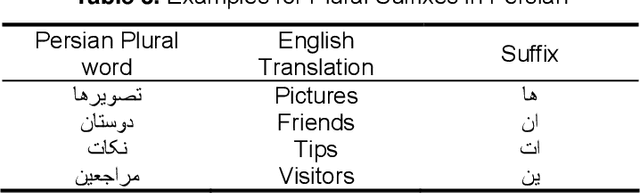
In the recent decade, with the enormous growth of digital content in internet and databases, sentiment analysis has received more and more attention between information retrieval and natural language processing researchers. Sentiment analysis aims to use automated tools to detect subjective information from reviews. One of the main challenges in sentiment analysis is feature selection. Feature selection is widely used as the first stage of analysis and classification tasks to reduce the dimension of problem, and improve speed by the elimination of irrelevant and redundant features. Up to now as there are few researches conducted on feature selection in sentiment analysis, there are very rare works for Persian sentiment analysis. This paper considers the problem of sentiment classification using different feature selection methods for online customer reviews in Persian language. Three of the challenges of Persian text are using of a wide variety of declensional suffixes, different word spacing and many informal or colloquial words. In this paper we study these challenges by proposing a model for sentiment classification of Persian review documents. The proposed model is based on lemmatization and feature selection and is employed Naive Bayes algorithm for classification. We evaluate the performance of the model on a manually gathered collection of cellphone reviews, where the results show the effectiveness of the proposed approaches.