 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning unbiased features
Paper and Code
Dec 17, 2014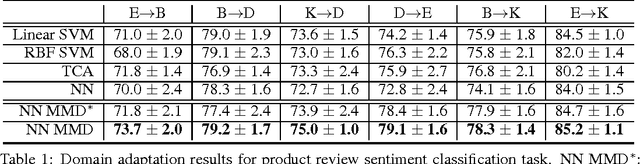



A key element in transfer learning is representation learning; if representations can be developed that expose the relevant factors underlying the data, then new tasks and domains can be learned readily based on mappings of these salient factors. We propose that an important aim for these representations are to be unbiased. Different forms of representation learning can be derived from alternative definitions of unwanted bias, e.g., bias to particular tasks, domains, or irrelevant underlying data dimensions. One very useful approach to estimating the amount of bias in a representation comes from maximum mean discrepancy (MMD) [5], a measure of distance between probability distributions. We are not the first to suggest that MMD can be a useful criterion in developing representations that apply across multiple domains or tasks [1]. However, in this paper we describe a number of novel applications of this criterion that we have devised, all based on the idea of developing unbiased representations. These formulations include: a standard domain adaptation framework; a method of learning invariant representations; an approach based on noise-insensitive autoencoders; and a novel form of generative model.