 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is a salient object? A dataset and a baseline model for salient object detection
Paper and Code
Dec 08, 2014

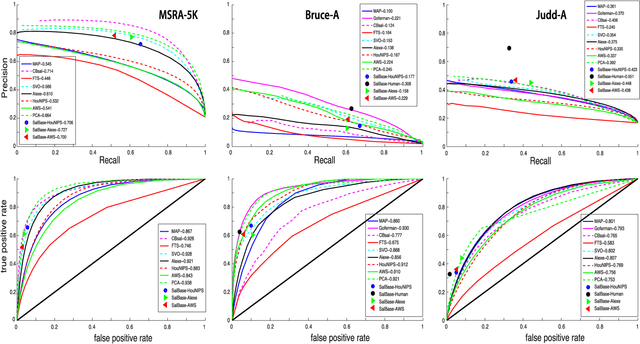
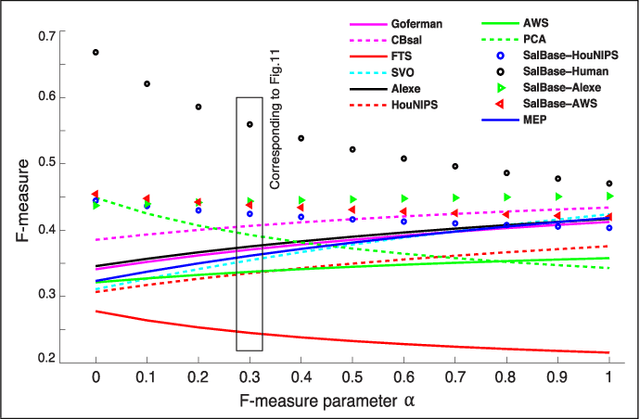
Salient object detection or salient region detection models, diverging from fixation prediction models, have traditionally been dealing with locating and segmenting the most salient object or region in a scene. While the notion of most salient object is sensible when multiple objects exist in a scene, current datasets for evaluation of saliency detection approaches often have scenes with only one single object. We introduce three main contributions in this paper: First, we take an indepth look at the problem of salient object detection by studying the relationship between where people look in scenes and what they choose as the most salient object when they are explicitly asked. Based on the agreement between fixations and saliency judgments, we then suggest that the most salient object is the one that attracts the highest fraction of fixations. Second, we provide two new less biased benchmark datasets containing scenes with multiple objects that challenge existing saliency models. Indeed, we observed a severe drop in performance of 8 state-of-the-art models on our datasets (40% to 70%). Third, we propose a very simple yet powerful model based on superpixels to be used as a baseline for model evaluation and comparison. While on par with the best models on MSRA-5K dataset, our model wins over other models on our data highlighting a serious drawback of existing models, which is convoluting the processes of locating the most salient object and its segmentation. We also provide a review and statistical analysis of some labeled scene datasets that can be used for evaluating salient object detection models. We believe that our work can greatly help remedy the over-fitting of models to existing biased datasets and opens new venues for future research in this fast-evolving field.