 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent-Neural-Network for Language Detection on Twitter Code-Switching Corpus
Paper and Code

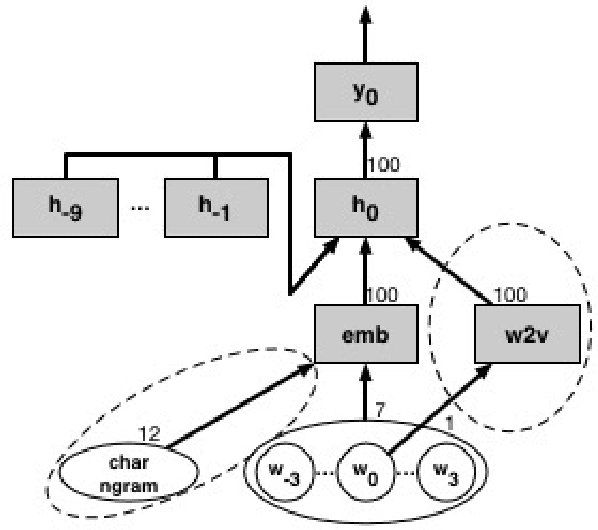
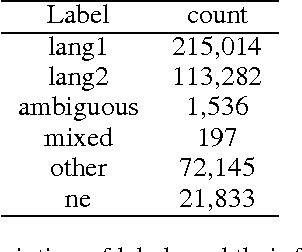
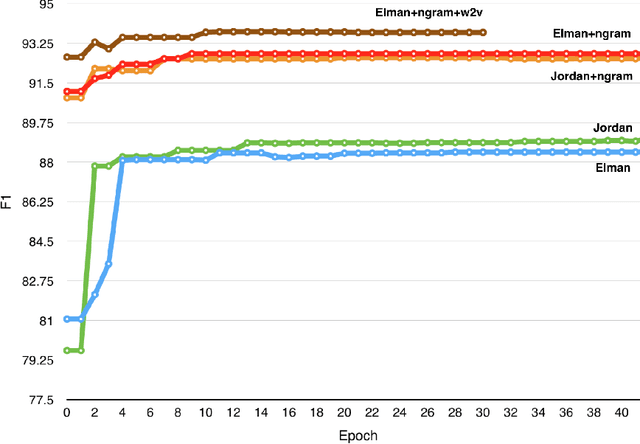
Mixed language data is one of the difficult yet less explored domains of natural language processing. Most research in fields like machine translation or sentiment analysis assume monolingual input. However, people who are capable of using more than one language often communicate using multiple languages at the same time. Sociolinguists believe this "code-switching" phenomenon to be socially motivated. For example, to express solidarity or to establish authority. Most past work depend on external tools or resources, such as part-of-speech tagging, dictionary look-up, or named-entity recognizers to extract rich features for training machine learning models. In this paper, we train recurrent neural networks with only raw features, and use word embedding to automatically learn meaningful representations. Using the same mixed-language Twitter corpus, our system is able to outperform the best SVM-based systems reported in the EMNLP'14 Code-Switching Workshop by 1% in accuracy, or by 17% in error rate reduction.