 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Pooling Approach to Modelling Spatial Relations for Image Retrieval and Annotation
Paper and Code
May 05, 2015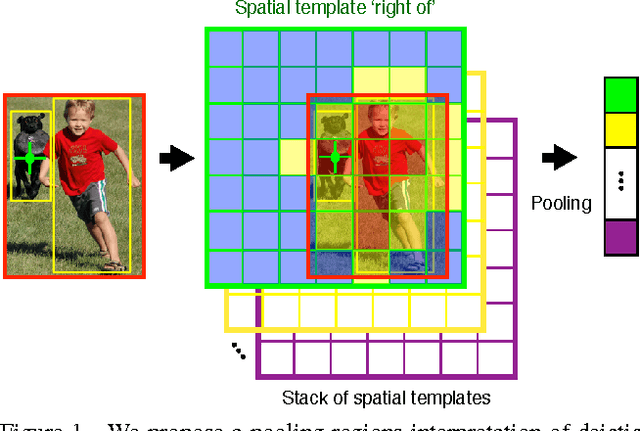

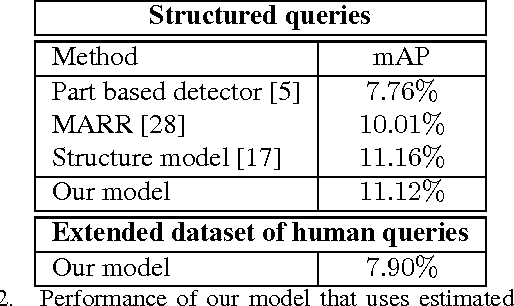

Over the last two decades we have witnessed strong progress on modeling visual object classes, scenes and attributes that have significantly contributed to automated image understanding. On the other hand, surprisingly little progress has been made on incorporating a spatial representation and reasoning in the inference process. In this work, we propose a pooling interpretation of spatial relations and show how it improves image retrieval and annotations tasks involving spatial language. Due to the complexity of the spatial language, we argue for a learning-based approach that acquires a representation of spatial relations by learning parameters of the pooling operator. We show improvements on previous work on two datasets and two different tasks as well as provide additional insights on a new dataset with an explicit focus on spatial relations.