Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Bayesian Modelling of Paired Symbols
Paper and Code
Sep 10, 2014
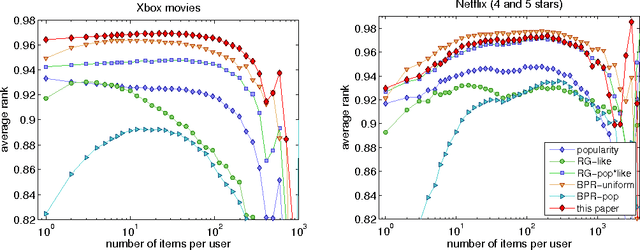
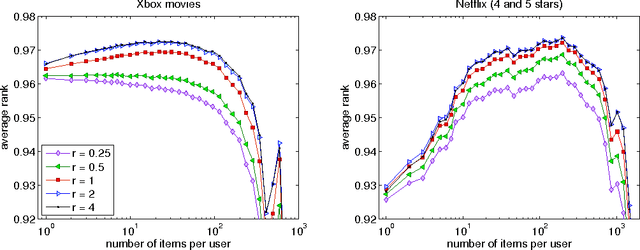
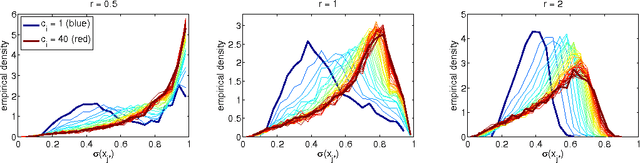
We present a novel, scalable and Bayesian approach to modelling the occurrence of pairs of symbols (i,j) drawn from a large vocabulary. Observed pairs are assumed to be generated by a simple popularity based selection process followed by censoring using a preference function. By basing inference on the well-founded principle of variational bounding, and using new site-independent bounds, we show how a scalable inference procedure can be obtained for large data sets. State of the art results are presented on real-world movie viewing data.
* 15 pages, 6 figures
View paper on