 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Feature Detectors: A bias in the repeatability criteria, and how to correct it
Paper and Code
Sep 09, 2014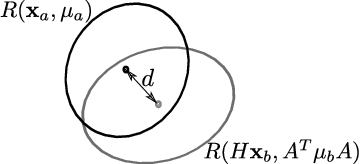
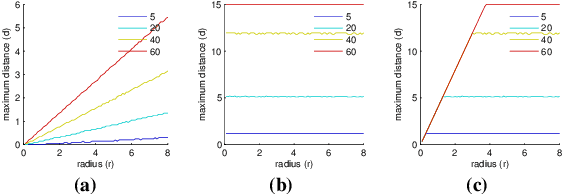


Most computer vision application rely on algorithms finding local correspondences between different images. These algorithms detect and compare stable local invariant descriptors centered at scale-invariant keypoints. Because of the importance of the problem, new keypoint detectors and descriptors are constantly being proposed, each one claiming to perform better (or to be complementary) to the preceding ones. This raises the question of a fair comparison between very diverse methods. This evaluation has been mainly based on a repeatability criterion of the keypoints under a series of image perturbations (blur, illumination, noise, rotations, homotheties, homographies, etc). In this paper, we argue that the classic repeatability criterion is biased towards algorithms producing redundant overlapped detections. To compensate this bias, we propose a variant of the repeatability rate taking into account the descriptors overlap. We apply this variant to revisit the popular benchmark by Mikolajczyk et al., on classic and new feature detectors. Experimental evidence shows that the hierarchy of these feature detectors is severely disrupted by the amended comparator.