Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping the Economic Crisis: Some Preliminary Investigations
Paper and Code
Jun 17, 2014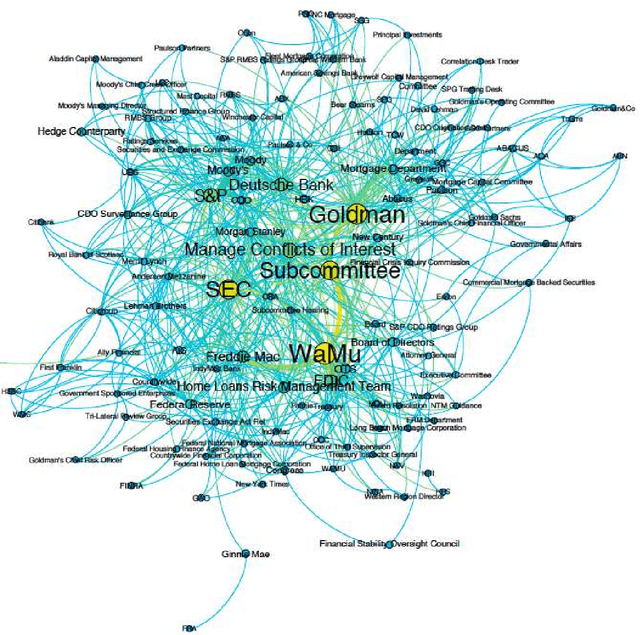
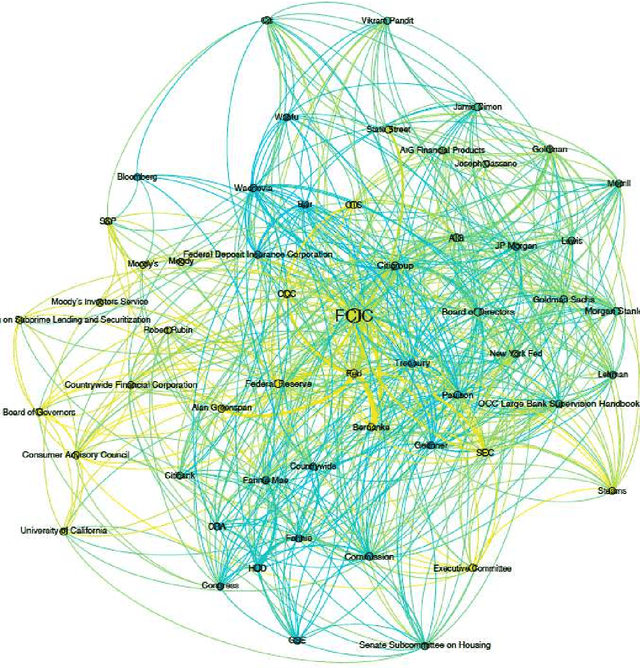
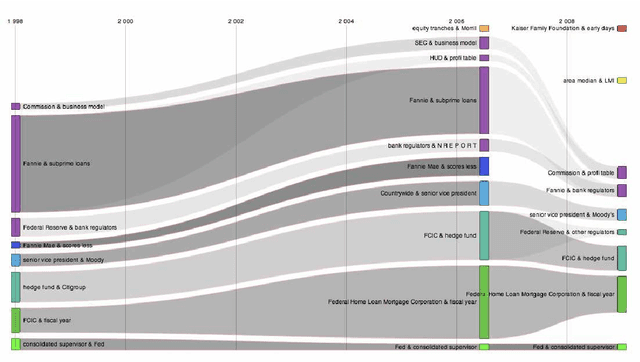
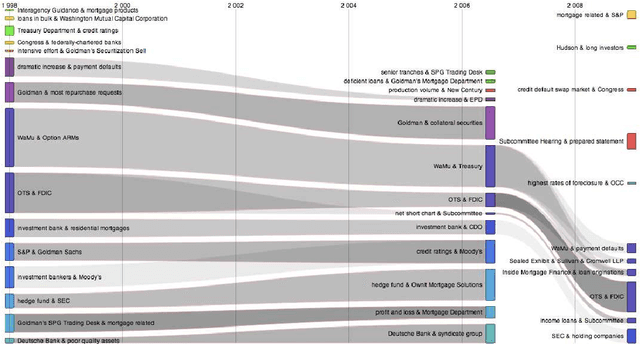
In this paper we describe our contribution to the PoliInformatics 2014 Challenge on the 2007-2008 financial crisis. We propose a state of the art technique to extract information from texts and provide different representations, giving first a static overview of the domain and then a dynamic representation of its main evolutions. We show that this strategy provides a practical solution to some recent theories in social sciences that are facing a lack of methods and tools to automatically extract information from natural language texts.
* Technical paper describing the Lattice submission to the 2014
PoliInformatics Unshared task
View paper on