 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA new keyphrases extraction method based on suffix tree data structure for arabic documents clustering
Paper and Code
Jan 22, 2014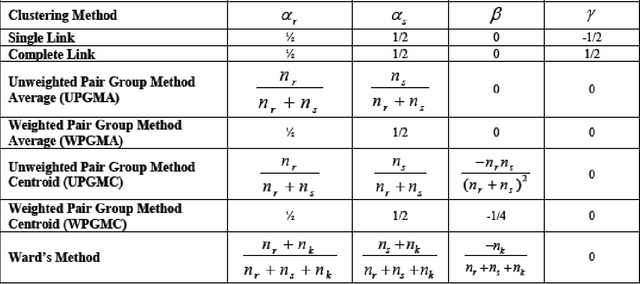
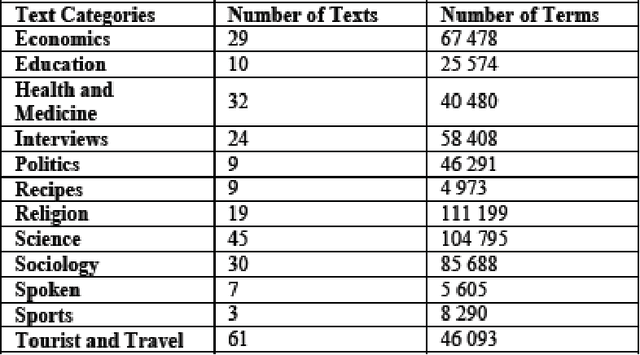
Document Clustering is a branch of a larger area of scientific study known as data mining .which is an unsupervised classification using to find a structure in a collection of unlabeled data. The useful information in the documents can be accompanied by a large amount of noise words when using Full Text Representation, and therefore will affect negatively the result of the clustering process. So it is with great need to eliminate the noise words and keeping just the useful information in order to enhance the quality of the clustering results. This problem occurs with different degree for any language such as English, European, Hindi, Chinese, and Arabic Language. To overcome this problem, in this paper, we propose a new and efficient Keyphrases extraction method based on the Suffix Tree data structure (KpST), the extracted Keyphrases are then used in the clustering process instead of Full Text Representation. The proposed method for Keyphrases extraction is language independent and therefore it may be applied to any language. In this investigation, we are interested to deal with the Arabic language which is one of the most complex languages. To evaluate our method, we conduct an experimental study on Arabic Documents using the most popular Clustering approach of Hierarchical algorithms: Agglomerative Hierarchical algorithm with seven linkage techniques and a variety of distance functions and similarity measures to perform Arabic Document Clustering task. The obtained results show that our method for extracting Keyphrases increases the quality of the clustering results. We propose also to study the effect of using the stemming for the testing dataset to cluster it with the same documents clustering techniques and similarity/distance measures.