 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighly comparative feature-based time-series classification
Paper and Code
May 09, 2014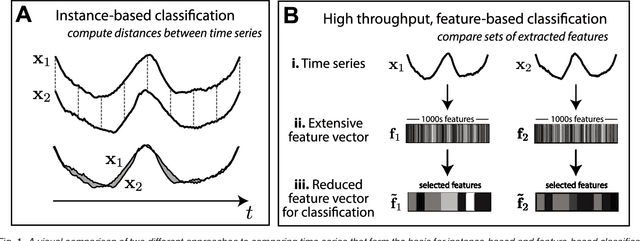
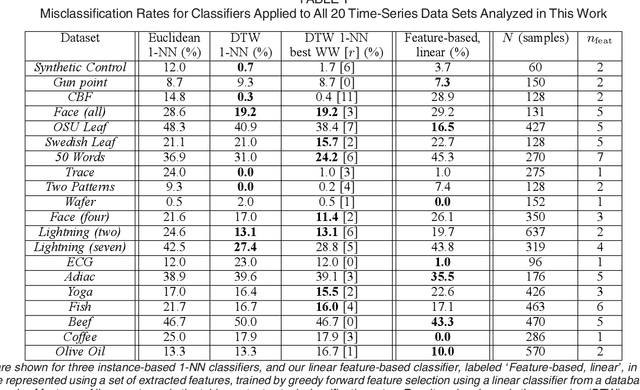
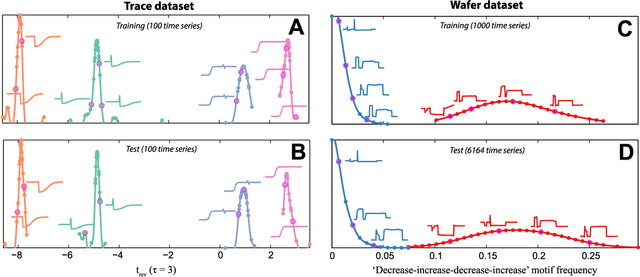
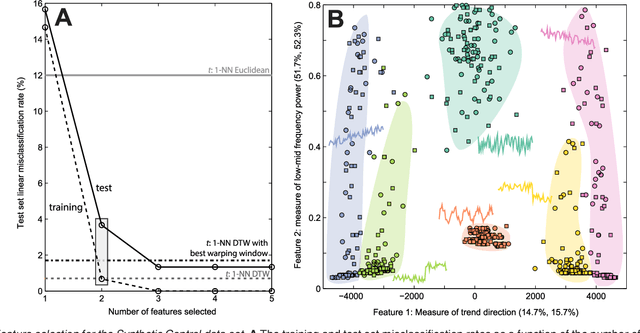
A highly comparative, feature-based approach to time series classification is introduced that uses an extensive database of algorithms to extract thousands of interpretable features from time series. These features are derived from across the scientific time-series analysis literature, and include summaries of time series in terms of their correlation structure, distribution, entropy, stationarity, scaling properties, and fits to a range of time-series models. After computing thousands of features for each time series in a training set, those that are most informative of the class structure are selected using greedy forward feature selection with a linear classifier. The resulting feature-based classifiers automatically learn the differences between classes using a reduced number of time-series properties, and circumvent the need to calculate distances between time series. Representing time series in this way results in orders of magnitude of dimensionality reduction, allowing the method to perform well on very large datasets containing long time series or time series of different lengths. For many of the datasets studied, classification performance exceeded that of conventional instance-based classifiers, including one nearest neighbor classifiers using Euclidean distances and dynamic time warping and, most importantly, the features selected provide an understanding of the properties of the dataset, insight that can guide further scientific investigation.