 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRectifying Self Organizing Maps for Automatic Concept Learning from Web Images
Paper and Code
Dec 16, 2013
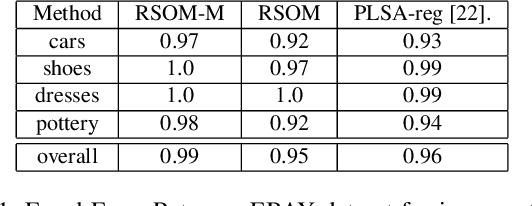
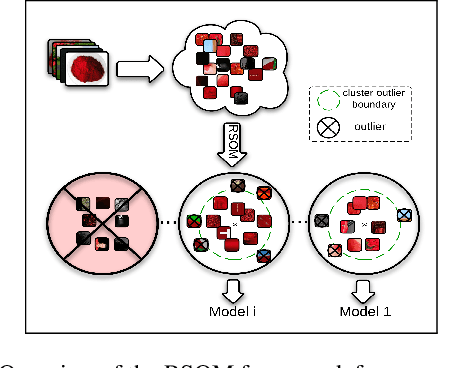
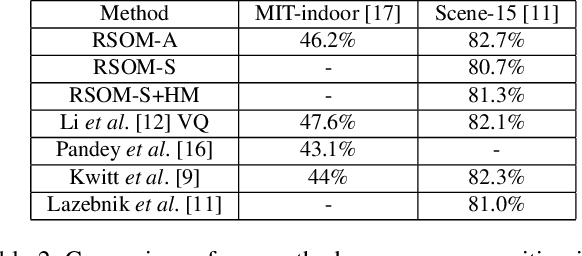
We attack the problem of learning concepts automatically from noisy web image search results. Going beyond low level attributes, such as colour and texture, we explore weakly-labelled datasets for the learning of higher level concepts, such as scene categories. The idea is based on discovering common characteristics shared among subsets of images by posing a method that is able to organise the data while eliminating irrelevant instances. We propose a novel clustering and outlier detection method, namely Rectifying Self Organizing Maps (RSOM). Given an image collection returned for a concept query, RSOM provides clusters pruned from outliers. Each cluster is used to train a model representing a different characteristics of the concept. The proposed method outperforms the state-of-the-art studies on the task of learning low-level concepts, and it is competitive in learning higher level concepts as well. It is capable to work at large scale with no supervision through exploiting the available sources.