 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre all training examples equally valuable?
Paper and Code
Nov 25, 2013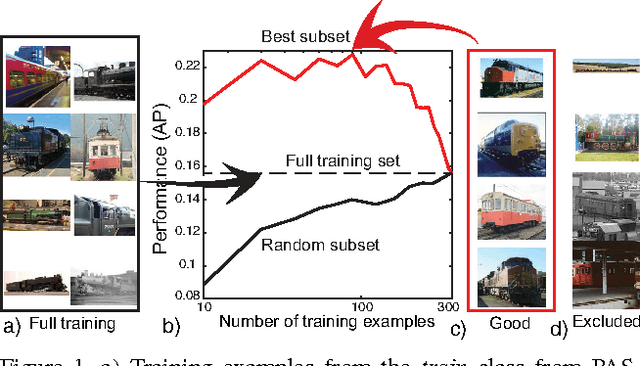

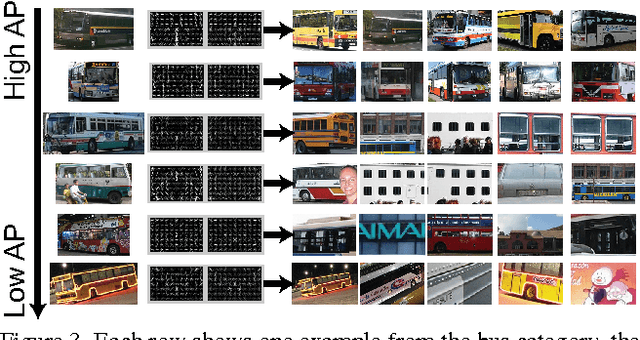
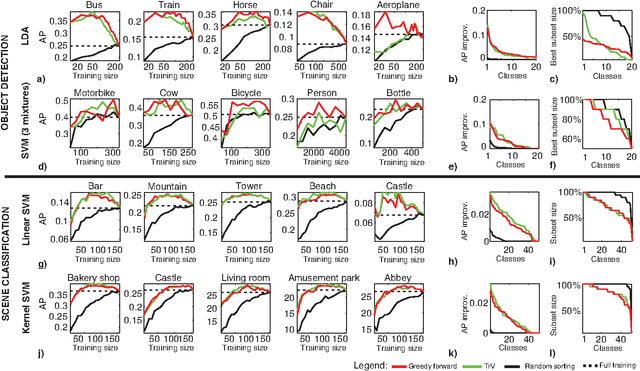
When learning a new concept, not all training examples may prove equally useful for training: some may have higher or lower training value than others. The goal of this paper is to bring to the attention of the vision community the following considerations: (1) some examples are better than others for training detectors or classifiers, and (2) in the presence of better examples, some examples may negatively impact performance and removing them may be beneficial. In this paper, we propose an approach for measuring the training value of an example, and use it for ranking and greedily sorting examples. We test our methods on different vision tasks, models, datasets and classifiers. Our experiments show that the performance of current state-of-the-art detectors and classifiers can be improved when training on a subset, rather than the whole training set.