 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Regularization with Covariance Dictionary for Linear Classifiers
Paper and Code
Oct 21, 2013
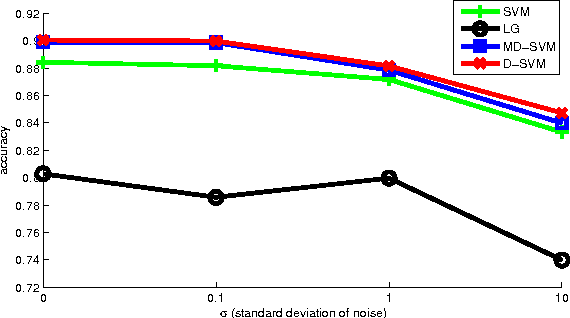


In this paper we propose a multi-task linear classifier learning problem called D-SVM (Dictionary SVM). D-SVM uses a dictionary of parameter covariance shared by all tasks to do multi-task knowledge transfer among different tasks. We formally define the learning problem of D-SVM and show two interpretations of this problem, from both the probabilistic and kernel perspectives. From the probabilistic perspective, we show that our learning formulation is actually a MAP estimation on all optimization variables. We also show its equivalence to a multiple kernel learning problem in which one is trying to find a re-weighting kernel for features from a dictionary of basis (despite the fact that only linear classifiers are learned). Finally, we describe an alternative optimization scheme to minimize the objective function and present empirical studies to valid our algorithm.