 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechniques for Feature Extraction In Speech Recognition System : A Comparative Study
Paper and Code
May 06, 2013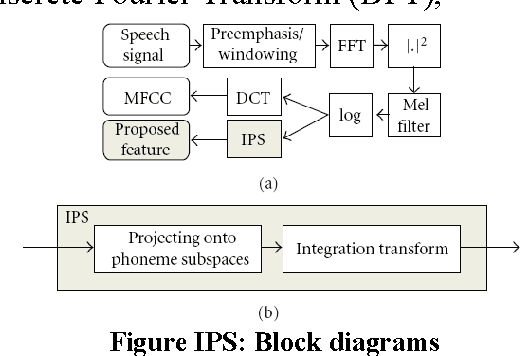
The time domain waveform of a speech signal carries all of the auditory information. From the phonological point of view, it little can be said on the basis of the waveform itself. However, past research in mathematics, acoustics, and speech technology have provided many methods for converting data that can be considered as information if interpreted correctly. In order to find some statistically relevant information from incoming data, it is important to have mechanisms for reducing the information of each segment in the audio signal into a relatively small number of parameters, or features. These features should describe each segment in such a characteristic way that other similar segments can be grouped together by comparing their features. There are enormous interesting and exceptional ways to describe the speech signal in terms of parameters. Though, they all have their strengths and weaknesses, we have presented some of the most used methods with their importance.