 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdverse Conditions and ASR Techniques for Robust Speech User Interface
Paper and Code
Mar 22, 2013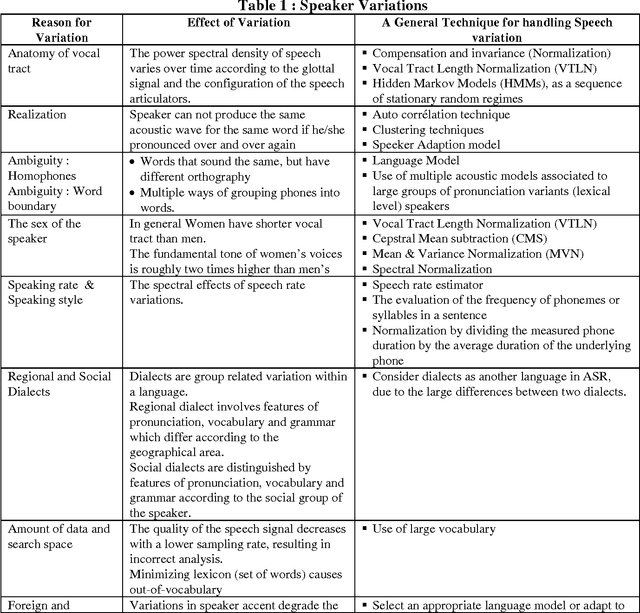
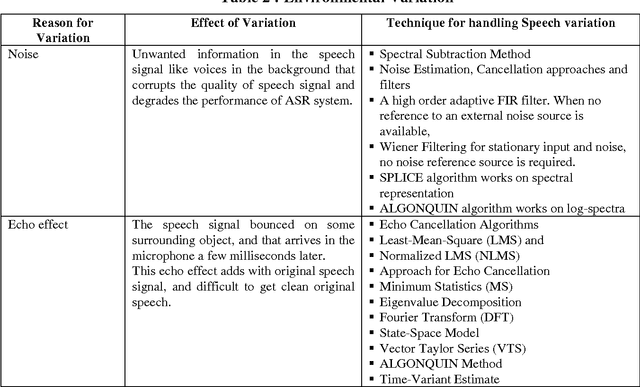
The main motivation for Automatic Speech Recognition (ASR) is efficient interfaces to computers, and for the interfaces to be natural and truly useful, it should provide coverage for a large group of users. The purpose of these tasks is to further improve man-machine communication. ASR systems exhibit unacceptable degradations in performance when the acoustical environments used for training and testing the system are not the same. The goal of this research is to increase the robustness of the speech recognition systems with respect to changes in the environment. A system can be labeled as environment-independent if the recognition accuracy for a new environment is the same or higher than that obtained when the system is retrained for that environment. Attaining such performance is the dream of the researchers. This paper elaborates some of the difficulties with Automatic Speech Recognition (ASR). These difficulties are classified into Speakers characteristics and environmental conditions, and tried to suggest some techniques to compensate variations in speech signal. This paper focuses on the robustness with respect to speakers variations and changes in the acoustical environment. We discussed several different external factors that change the environment and physiological differences that affect the performance of a speech recognition system followed by techniques that are helpful to design a robust ASR system.