 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolynomial Value Iteration Algorithms for Detrerminstic MDPs
Paper and Code
Dec 12, 2012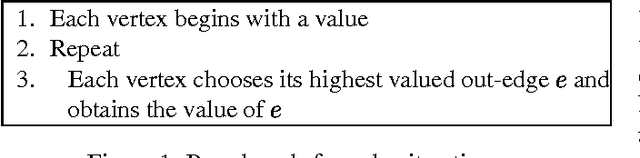
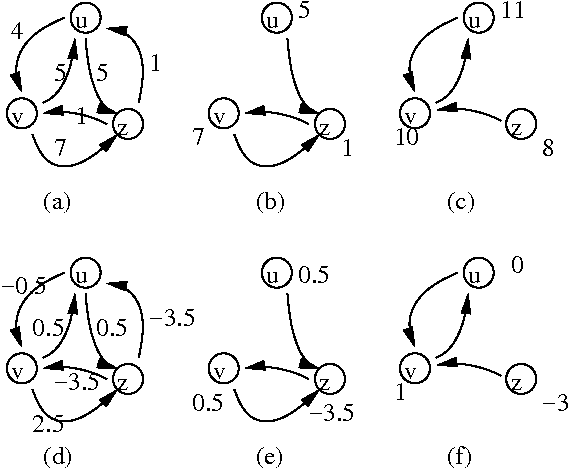
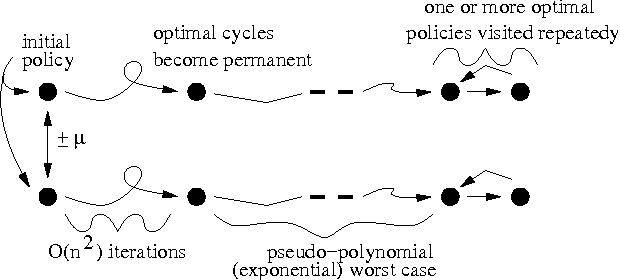
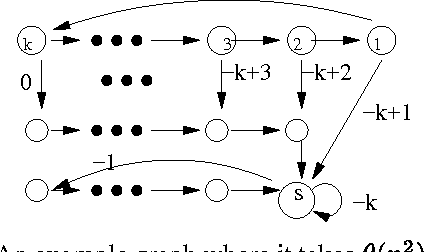
Value iteration is a commonly used and empirically competitive method in solving many Markov decision process problems. However, it is known that value iteration has only pseudo-polynomial complexity in general. We establish a somewhat surprising polynomial bound for value iteration on deterministic Markov decision (DMDP) problems. We show that the basic value iteration procedure converges to the highest average reward cycle on a DMDP problem in heta(n^2) iterations, or heta(mn^2) total time, where n denotes the number of states, and m the number of edges. We give two extensions of value iteration that solve the DMDP in heta(mn) time. We explore the analysis of policy iteration algorithms and report on an empirical study of value iteration showing that its convergence is much faster on random sparse graphs.