 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Users From Their Rating Patterns
Paper and Code
Jul 26, 2012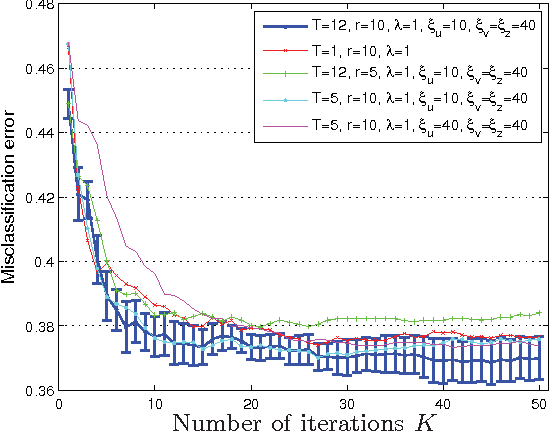
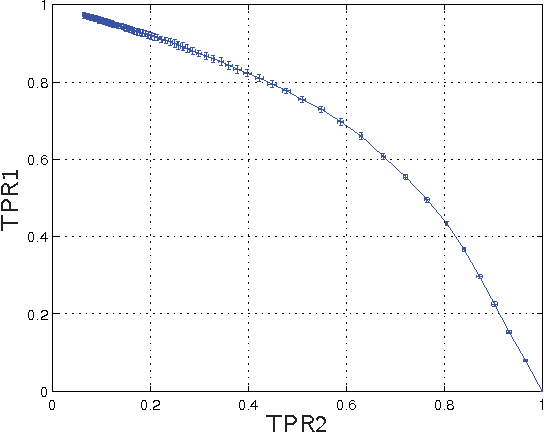

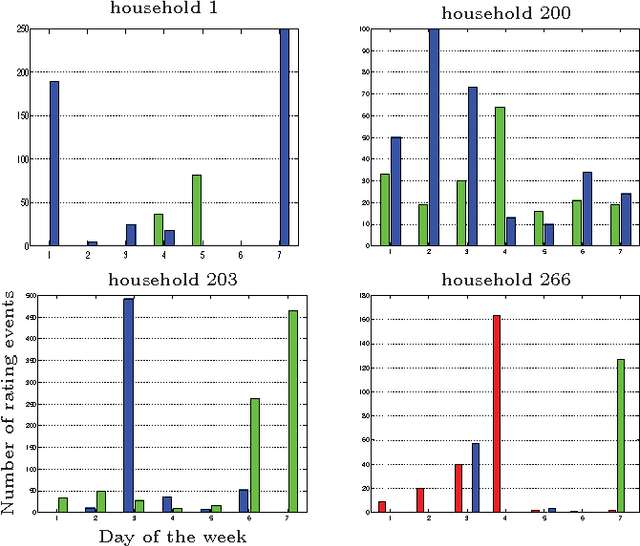
This paper reports on our analysis of the 2011 CAMRa Challenge dataset (Track 2) for context-aware movie recommendation systems. The train dataset comprises 4,536,891 ratings provided by 171,670 users on 23,974$ movies, as well as the household groupings of a subset of the users. The test dataset comprises 5,450 ratings for which the user label is missing, but the household label is provided. The challenge required to identify the user labels for the ratings in the test set. Our main finding is that temporal information (time labels of the ratings) is significantly more useful for achieving this objective than the user preferences (the actual ratings). Using a model that leverages on this fact, we are able to identify users within a known household with an accuracy of approximately 96% (i.e. misclassification rate around 4%).