 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFST Based Morphological Analyzer for Hindi Language
Paper and Code
Jul 23, 2012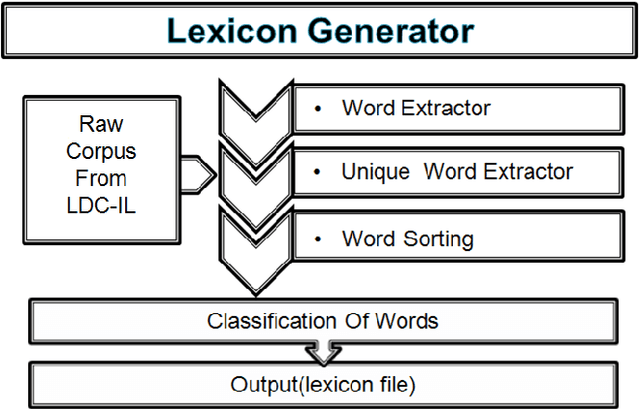
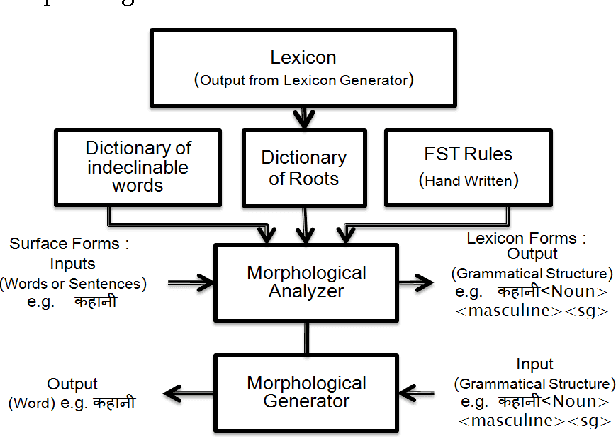
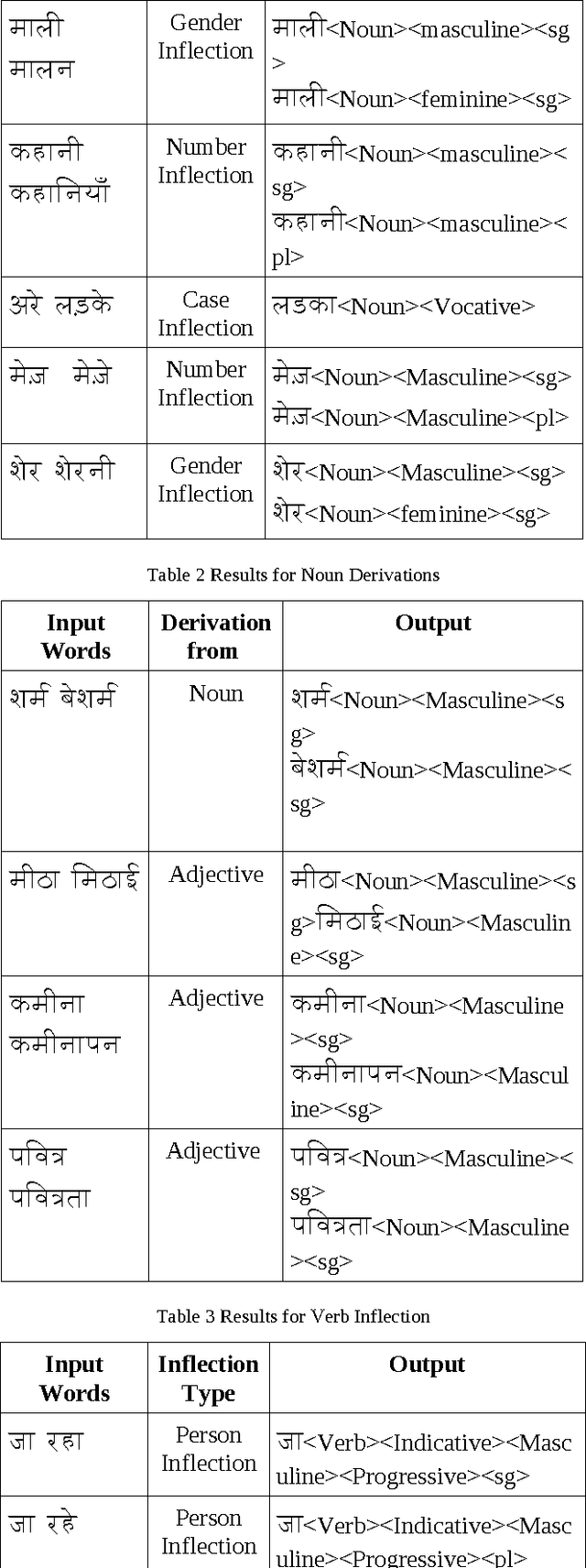
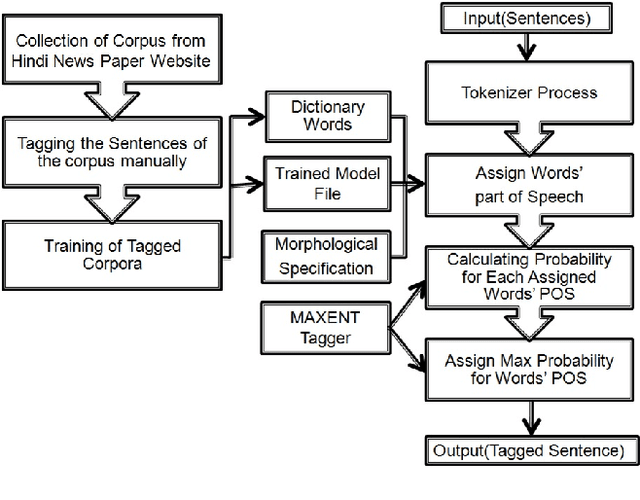
Hindi being a highly inflectional language, FST (Finite State Transducer) based approach is most efficient for developing a morphological analyzer for this language. The work presented in this paper uses the SFST (Stuttgart Finite State Transducer) tool for generating the FST. A lexicon of root words is created. Rules are then added for generating inflectional and derivational words from these root words. The Morph Analyzer developed was used in a Part Of Speech (POS) Tagger based on Stanford POS Tagger. The system was first trained using a manually tagged corpus and MAXENT (Maximum Entropy) approach of Stanford POS tagger was then used for tagging input sentences. The morphological analyzer gives approximately 97% correct results. POS tagger gives an accuracy of approximately 87% for the sentences that have the words known to the trained model file, and 80% accuracy for the sentences that have the words unknown to the trained model file.