Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Entropy for Collaborative Filtering
Paper and Code
Jul 11, 2012
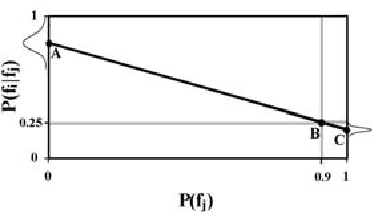
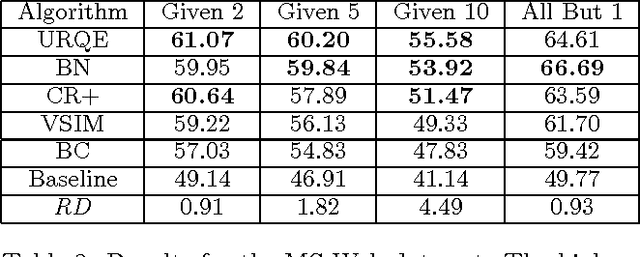

Within the task of collaborative filtering two challenges for computing conditional probabilities exist. First, the amount of training data available is typically sparse with respect to the size of the domain. Thus, support for higher-order interactions is generally not present. Second, the variables that we are conditioning upon vary for each query. That is, users label different variables during each query. For this reason, there is no consistent input to output mapping. To address these problems we purpose a maximum entropy approach using a non-standard measure of entropy. This approach can be simplified to solving a set of linear equations that can be efficiently solved.
* Appears in Proceedings of the Twentieth Conference on Uncertainty in
Artificial Intelligence (UAI2004)
View paper on