 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Life-long Off-policy Learning
Paper and Code
Jun 27, 2012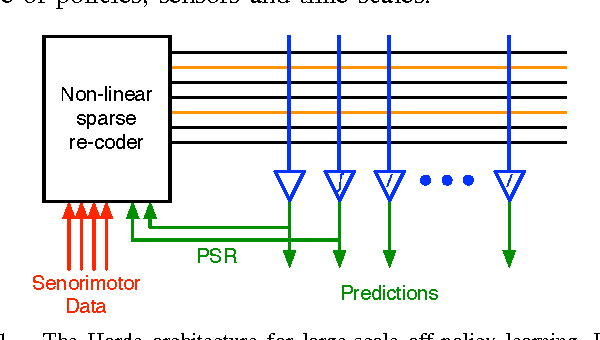

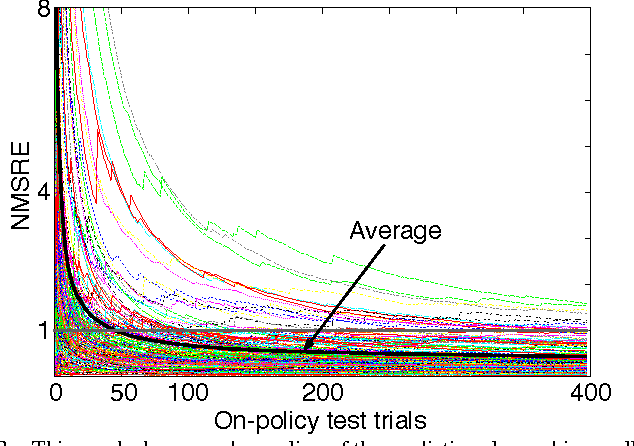
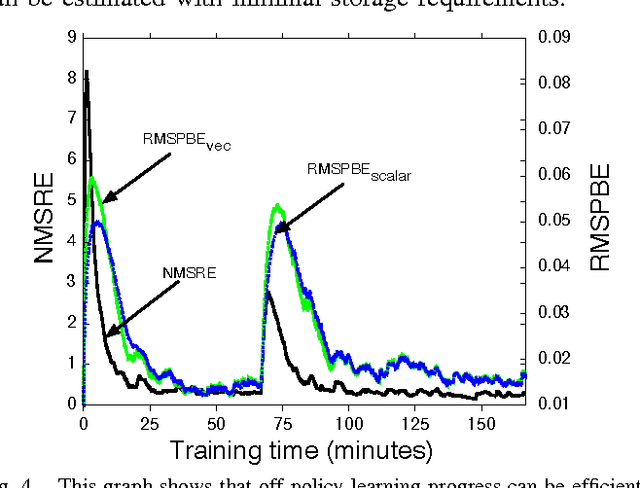
We pursue a life-long learning approach to artificial intelligence that makes extensive use of reinforcement learning algorithms. We build on our prior work with general value functions (GVFs) and the Horde architecture. GVFs have been shown able to represent a wide variety of facts about the world's dynamics that may be useful to a long-lived agent (Sutton et al. 2011). We have also previously shown scaling - that thousands of on-policy GVFs can be learned accurately in real-time on a mobile robot (Modayil, White & Sutton 2011). That work was limited in that it learned about only one policy at a time, whereas the greatest potential benefits of life-long learning come from learning about many policies in parallel, as we explore in this paper. Many new challenges arise in this off-policy learning setting. To deal with convergence and efficiency challenges, we utilize the recently introduced GTD({\lambda}) algorithm. We show that GTD({\lambda}) with tile coding can simultaneously learn hundreds of predictions for five simple target policies while following a single random behavior policy, assessing accuracy with interspersed on-policy tests. To escape the need for the tests, which preclude further scaling, we introduce and empirically vali- date two online estimators of the off-policy objective (MSPBE). Finally, we use the more efficient of the two estimators to demonstrate off-policy learning at scale - the learning of value functions for one thousand policies in real time on a physical robot. This ability constitutes a significant step towards scaling life-long off-policy learning.