 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrimination of English to other Indian languages (Kannada and Hindi) for OCR system
Paper and Code
May 10, 2012
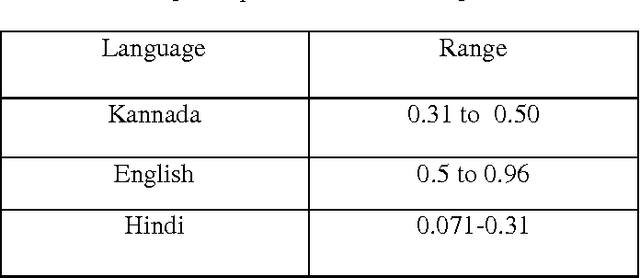

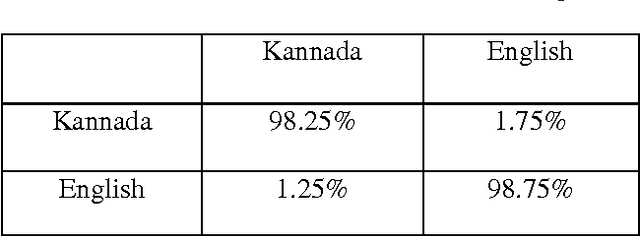
India is a multilingual multi-script country. In every state of India there are two languages one is state local language and the other is English. For example in Andhra Pradesh, a state in India, the document may contain text words in English and Telugu script. For Optical Character Recognition (OCR) of such a bilingual document, it is necessary to identify the script before feeding the text words to the OCRs of individual scripts. In this paper, we are introducing a simple and efficient technique of script identification for Kannada, English and Hindi text words of a printed document. The proposed approach is based on the horizontal and vertical projection profile for the discrimination of the three scripts. The feature extraction is done based on the horizontal projection profile of each text words. We analysed 700 different words of Kannada, English and Hindi in order to extract the discrimination features and for the development of knowledge base. We use the horizontal projection profile of each text word and based on the horizontal projection profile we extract the appropriate features. The proposed system is tested on 100 different document images containing more than 1000 text words of each script and a classification rate of 98.25%, 99.25% and 98.87% is achieved for Kannada, English and Hindi respectively.