 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view predictive partitioning in high dimensions
Paper and Code
Feb 02, 2012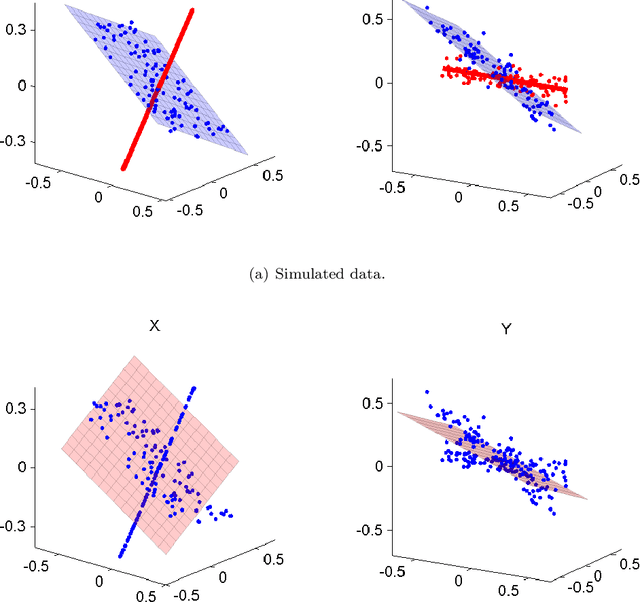
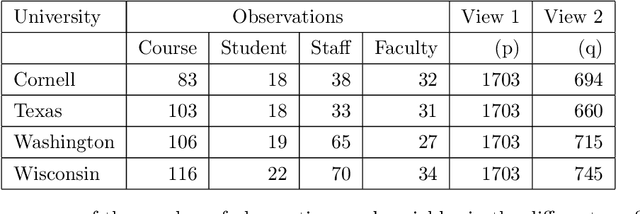
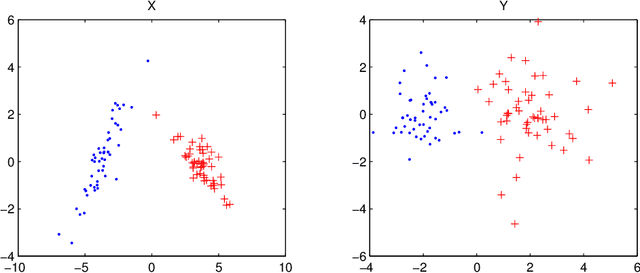
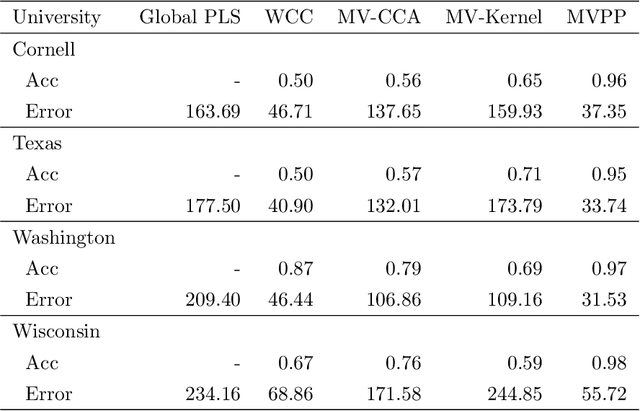
Many modern data mining applications are concerned with the analysis of datasets in which the observations are described by paired high-dimensional vectorial representations or "views". Some typical examples can be found in web mining and genomics applications. In this article we present an algorithm for data clustering with multiple views, Multi-View Predictive Partitioning (MVPP), which relies on a novel criterion of predictive similarity between data points. We assume that, within each cluster, the dependence between multivariate views can be modelled by using a two-block partial least squares (TB-PLS) regression model, which performs dimensionality reduction and is particularly suitable for high-dimensional settings. The proposed MVPP algorithm partitions the data such that the within-cluster predictive ability between views is maximised. The proposed objective function depends on a measure of predictive influence of points under the TB-PLS model which has been derived as an extension of the PRESS statistic commonly used in ordinary least squares regression. Using simulated data, we compare the performance of MVPP to that of competing multi-view clustering methods which rely upon geometric structures of points, but ignore the predictive relationship between the two views. State-of-art results are obtained on benchmark web mining datasets.