 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian and L1 Approaches to Sparse Unsupervised Learning
Paper and Code
Aug 17, 2012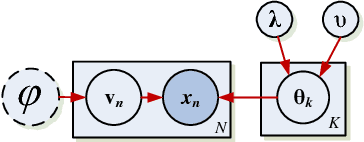
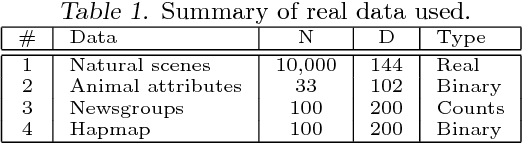
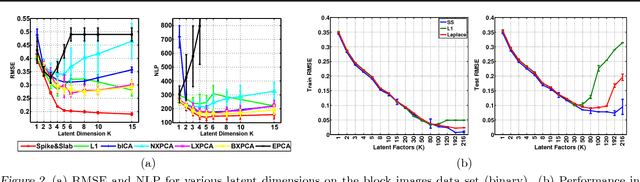
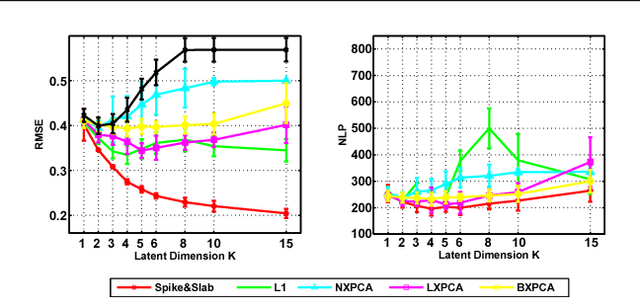
The use of L1 regularisation for sparse learning has generated immense research interest, with successful application in such diverse areas as signal acquisition, image coding, genomics and collaborative filtering. While existing work highlights the many advantages of L1 methods, in this paper we find that L1 regularisation often dramatically underperforms in terms of predictive performance when compared with other methods for inferring sparsity. We focus on unsupervised latent variable models, and develop L1 minimising factor models, Bayesian variants of "L1", and Bayesian models with a stronger L0-like sparsity induced through spike-and-slab distributions. These spike-and-slab Bayesian factor models encourage sparsity while accounting for uncertainty in a principled manner and avoiding unnecessary shrinkage of non-zero values. We demonstrate on a number of data sets that in practice spike-and-slab Bayesian methods outperform L1 minimisation, even on a computational budget. We thus highlight the need to re-assess the wide use of L1 methods in sparsity-reliant applications, particularly when we care about generalising to previously unseen data, and provide an alternative that, over many varying conditions, provides improved generalisation performance.