 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum-Like Uncertain Conditionals for Text Analysis
Paper and Code
Jun 02, 2011
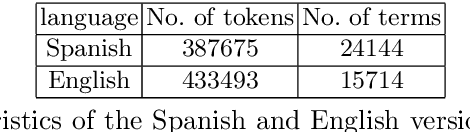
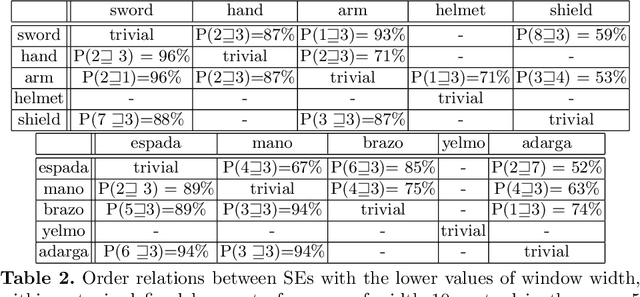
Simple representations of documents based on the occurrences of terms are ubiquitous in areas like Information Retrieval, and also frequent in Natural Language Processing. In this work we propose a logical-probabilistic approach to the analysis of natural language text based in the concept of Uncertain Conditional, on top of a formulation of lexical measurements inspired in the theoretical concept of ideal quantum measurements. The proposed concept can be used for generating topic-specific representations of text, aiming to match in a simple way the perception of a user with a pre-established idea of what the usage of terms in the text should be. A simple example is developed with two versions of a text in two languages, showing how regularities in the use of terms are detected and easily represented.