 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Choice Models
Paper and Code
Sep 21, 2011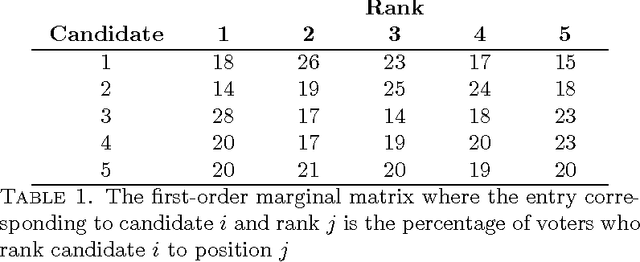
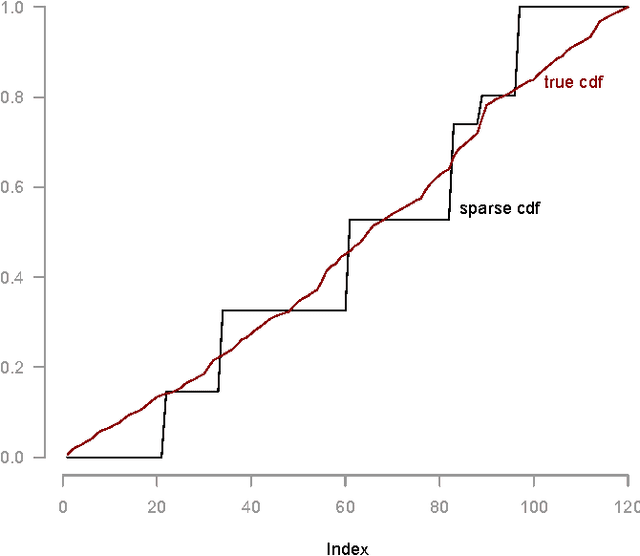
Choice models, which capture popular preferences over objects of interest, play a key role in making decisions whose eventual outcome is impacted by human choice behavior. In most scenarios, the choice model, which can effectively be viewed as a distribution over permutations, must be learned from observed data. The observed data, in turn, may frequently be viewed as (partial, noisy) information about marginals of this distribution over permutations. As such, the search for an appropriate choice model boils down to learning a distribution over permutations that is (near-)consistent with observed information about this distribution. In this work, we pursue a non-parametric approach which seeks to learn a choice model (i.e. a distribution over permutations) with {\em sparsest} possible support, and consistent with observed data. We assume that the data observed consists of noisy information pertaining to the marginals of the choice model we seek to learn. We establish that {\em any} choice model admits a `very' sparse approximation in the sense that there exists a choice model whose support is small relative to the dimension of the observed data and whose marginals approximately agree with the observed marginal information. We further show that under, what we dub, `signature' conditions, such a sparse approximation can be found in a computationally efficiently fashion relative to a brute force approach. An empirical study using the American Psychological Association election data-set suggests that our approach manages to unearth useful structural properties of the underlying choice model using the sparse approximation found. Our results further suggest that the signature condition is a potential alternative to the recently popularized Restricted Null Space condition for efficient recovery of sparse models.