 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Objective Genetic Programming Projection Pursuit for Exploratory Data Modeling
Paper and Code
Oct 10, 2010
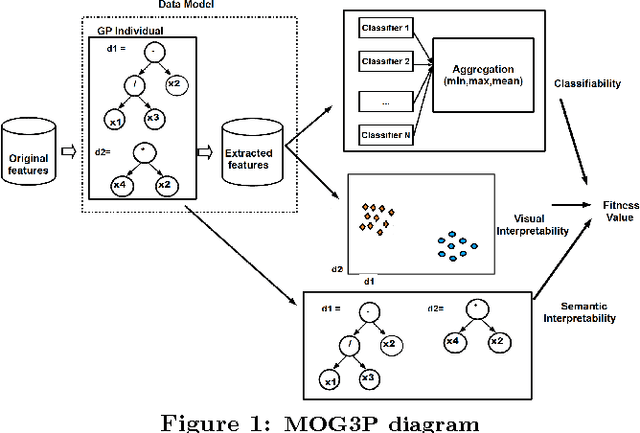
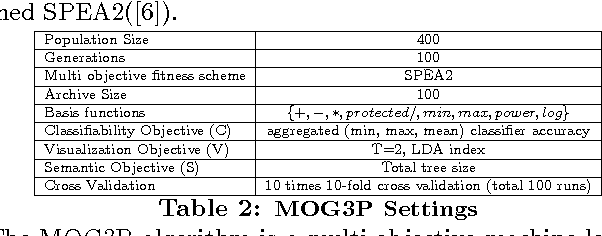
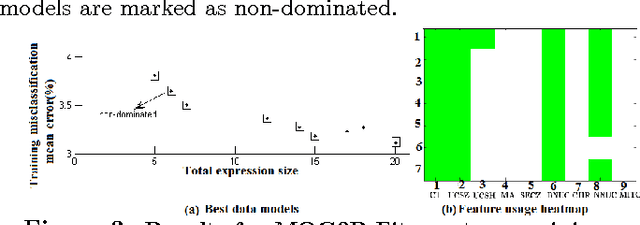
For classification problems, feature extraction is a crucial process which aims to find a suitable data representation that increases the performance of the machine learning algorithm. According to the curse of dimensionality theorem, the number of samples needed for a classification task increases exponentially as the number of dimensions (variables, features) increases. On the other hand, it is costly to collect, store and process data. Moreover, irrelevant and redundant features might hinder classifier performance. In exploratory analysis settings, high dimensionality prevents the users from exploring the data visually. Feature extraction is a two-step process: feature construction and feature selection. Feature construction creates new features based on the original features and feature selection is the process of selecting the best features as in filter, wrapper and embedded methods. In this work, we focus on feature construction methods that aim to decrease data dimensionality for visualization tasks. Various linear (such as principal components analysis (PCA), multiple discriminants analysis (MDA), exploratory projection pursuit) and non-linear (such as multidimensional scaling (MDS), manifold learning, kernel PCA/LDA, evolutionary constructive induction) techniques have been proposed for dimensionality reduction. Our algorithm is an adaptive feature extraction method which consists of evolutionary constructive induction for feature construction and a hybrid filter/wrapper method for feature selection.