 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Classification using Association Rule with a Hybrid Concept of Naive Bayes Classifier and Genetic Algorithm
Paper and Code
Sep 25, 2010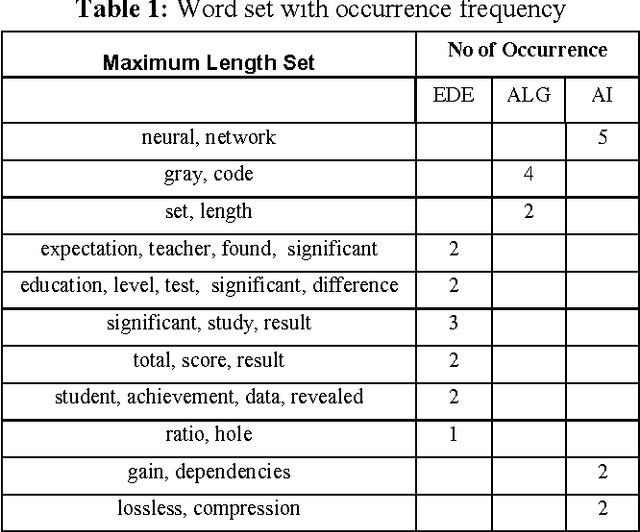
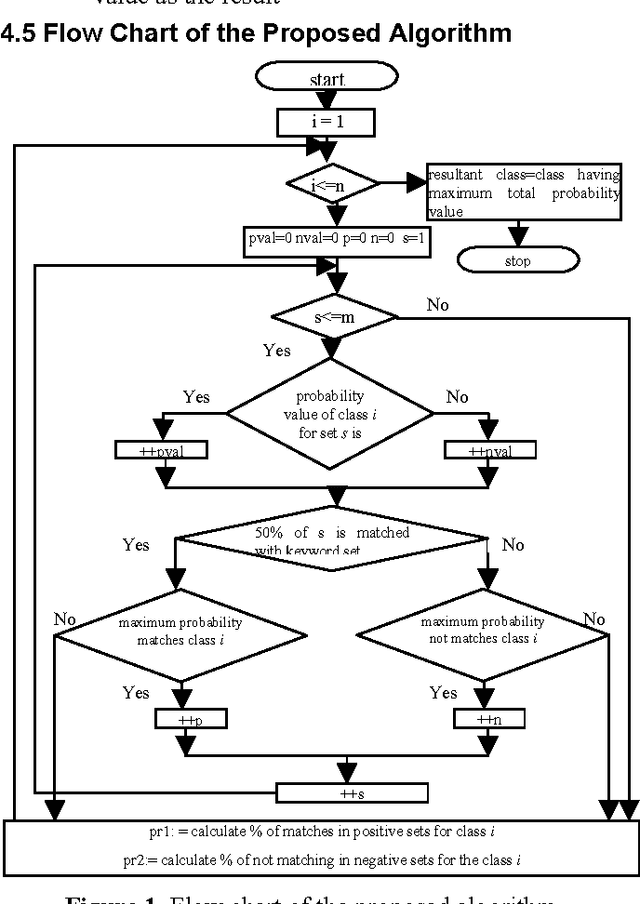
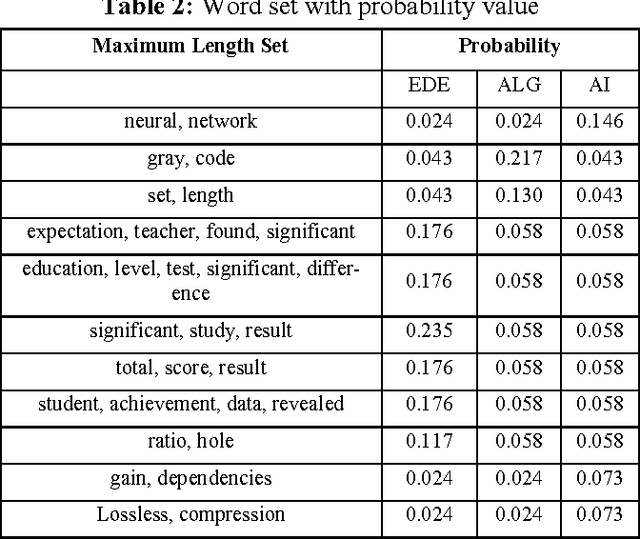
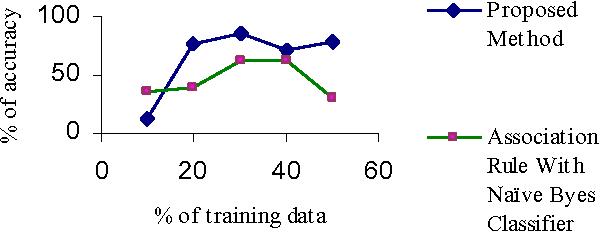
Text classification is the automated assignment of natural language texts to predefined categories based on their content. Text classification is the primary requirement of text retrieval systems, which retrieve texts in response to a user query, and text understanding systems, which transform text in some way such as producing summaries, answering questions or extracting data. Now a day the demand of text classification is increasing tremendously. Keeping this demand into consideration, new and updated techniques are being developed for the purpose of automated text classification. This paper presents a new algorithm for text classification. Instead of using words, word relation i.e. association rules is used to derive feature set from pre-classified text documents. The concept of Naive Bayes Classifier is then used on derived features and finally a concept of Genetic Algorithm has been added for final classification. A system based on the proposed algorithm has been implemented and tested. The experimental results show that the proposed system works as a successful text classifier.