 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutlier Detection Using Nonconvex Penalized Regression
Paper and Code
Oct 17, 2011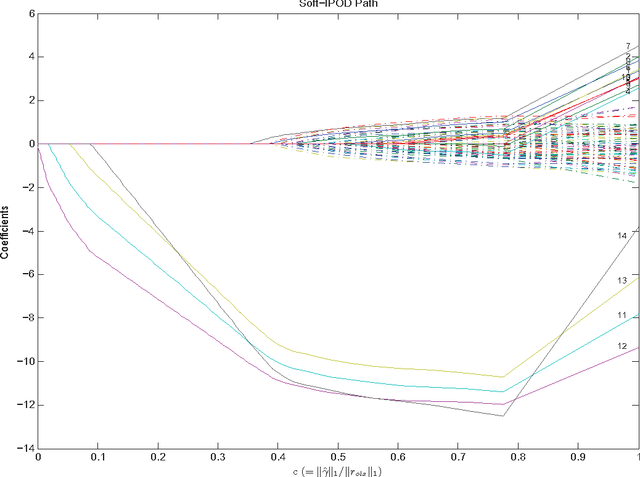
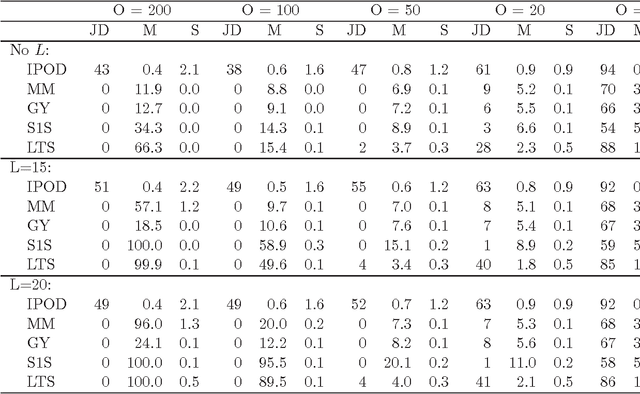
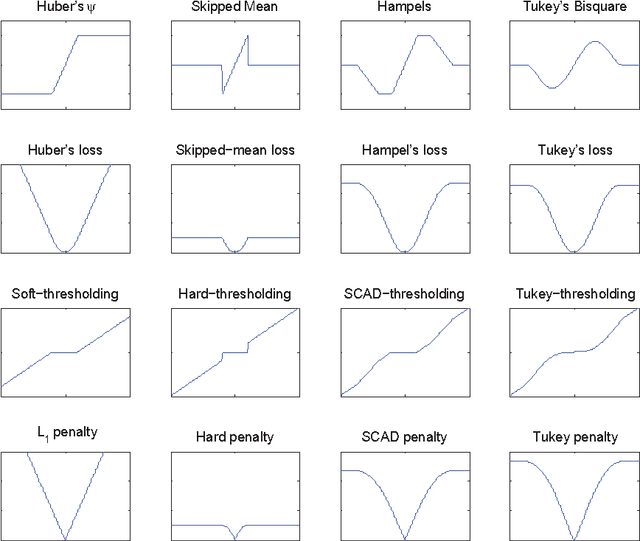
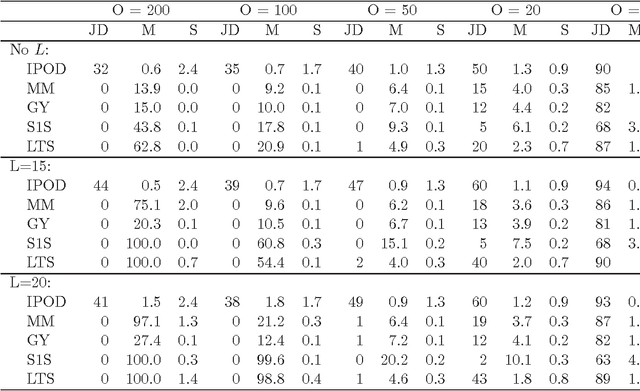
This paper studies the outlier detection problem from the point of view of penalized regressions. Our regression model adds one mean shift parameter for each of the $n$ data points. We then apply a regularization favoring a sparse vector of mean shift parameters. The usual $L_1$ penalty yields a convex criterion, but we find that it fails to deliver a robust estimator. The $L_1$ penalty corresponds to soft thresholding. We introduce a thresholding (denoted by $\Theta$) based iterative procedure for outlier detection ($\Theta$-IPOD). A version based on hard thresholding correctly identifies outliers on some hard test problems. We find that $\Theta$-IPOD is much faster than iteratively reweighted least squares for large data because each iteration costs at most $O(np)$ (and sometimes much less) avoiding an $O(np^2)$ least squares estimate. We describe the connection between $\Theta$-IPOD and $M$-estimators. Our proposed method has one tuning parameter with which to both identify outliers and estimate regression coefficients. A data-dependent choice can be made based on BIC. The tuned $\Theta$-IPOD shows outstanding performance in identifying outliers in various situations in comparison to other existing approaches. This methodology extends to high-dimensional modeling with $p\gg n$, if both the coefficient vector and the outlier pattern are sparse.